Feeding the GPU in Deep Learning
Context (title): Feeding the GPU in Deep Learning
Finally, the time to run VGG on CIFAR was reduced from a day to an hour, and running the MobileNet model on ImageNet only takes 2 minutes per epoch. (Code is at the end of the article)
When running CIFAR, if you only use the torchvision dataloader (with the most common padding/crop/flip for data augmentation), it will be very slow. The speed is roughly as shown below, taking more than a day to complete 600 epochs, and the speed is inconsistent.

Initially, I thought it was an I/O issue, so I mounted a memory disk and changed the path to continue using the torchvision dataloader, but the speed didn’t change much…

Then I checked the resource usage and found that the CPU usage was almost maxed out (I could only request 2 CPUs and one V100…), but the GPU usage was very low, which basically confirmed that the bottleneck was the CPU processing speed.
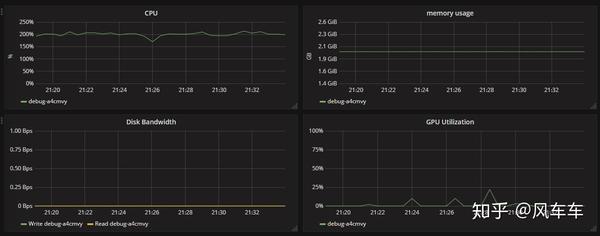
Later, I found some information that NVIDIA has a library called DALI that can use the GPU for image preprocessing, providing a complete pipeline from input, decoding to transformation. It includes common operations like pad/crop and supports various frameworks such as PyTorch/Caffe/MXNet.
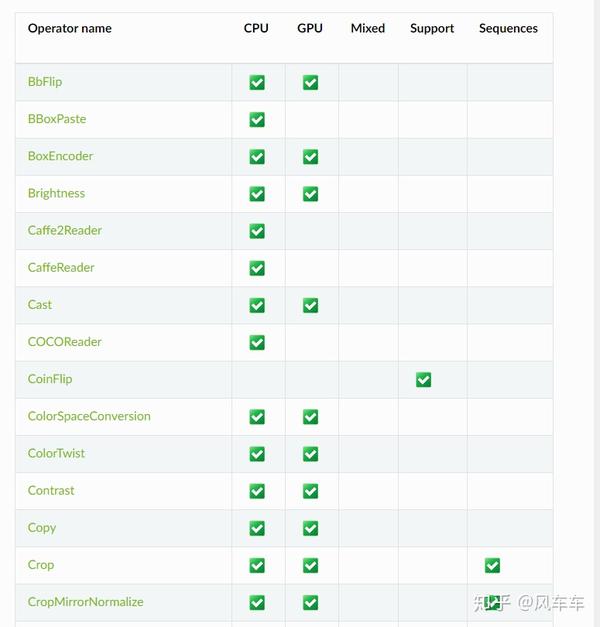
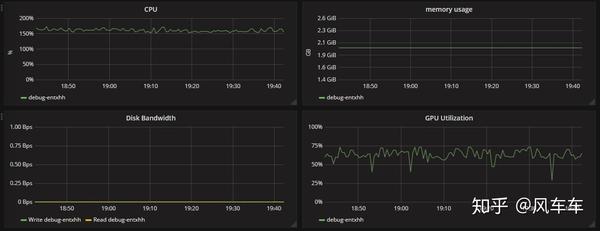
Unfortunately, I couldn’t find a CIFAR pipeline in the official documentation, so I wrote one myself based on the ImageNet version. Initially, I encountered some pitfalls (I used a JPEG version of CIFAR for decoding to save time, which resulted in a significant drop in accuracy without an apparent reason, so I had to read from CIFAR’s binary files). In the end, I achieved the same accuracy, and looking at the speed and resource usage, the total time was reduced from a day to an hour, and GPU usage increased significantly.

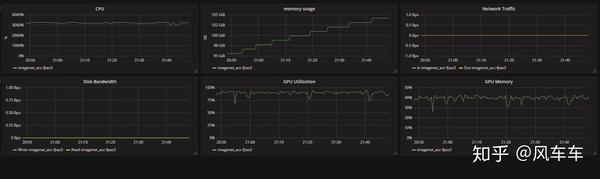
Regarding ImageNet training acceleration, I initially copied the entire dataset to the mounted memory disk (160GB was roughly enough, taking less than 10 minutes from copying to decompression). I found that using the torchvision dataloader for training was also unstable, so I directly used DALI’s official dataloader, and the speed took off as well (couldn’t find the training images from that time). Then, combined with Apex for mixed precision and distributed training, requesting 4 V100s, GPU usage could stabilize above 95, and with 8 V100s, it could stabilize above 90. Finally, with 16 V100s and 32 CPUs, it could stabilize around 85 (resource usage showed CPU maxed out, otherwise GPU could probably reach above 95). Running MobileNet on ImageNet with 16 V100s only takes 2 minutes per epoch.
The dataloader I wrote is on GitHub. The accuracy I tested is similar to the torchvision version, but the speed is much faster. I’ll also write some other common dataloader DALI versions and upload them when I have time.