Efficient Dense Modules of Asymmetric Convolution for Real-Time Semantic Segmentation
Abstract
Previous networks for segmentation were either slow or had low accuracy. Here, an EDANet module is designed, combining asymmetric convolution, dilated convolution, and dense connectivity. It outperforms FCN in various aspects and does not include a decoder structure, context module, post-processing scheme, or pretrained model. Experiments were conducted on Cityscapes and CamVid.
1. Introduction
A comparison of EDANet with other networks is shown below: 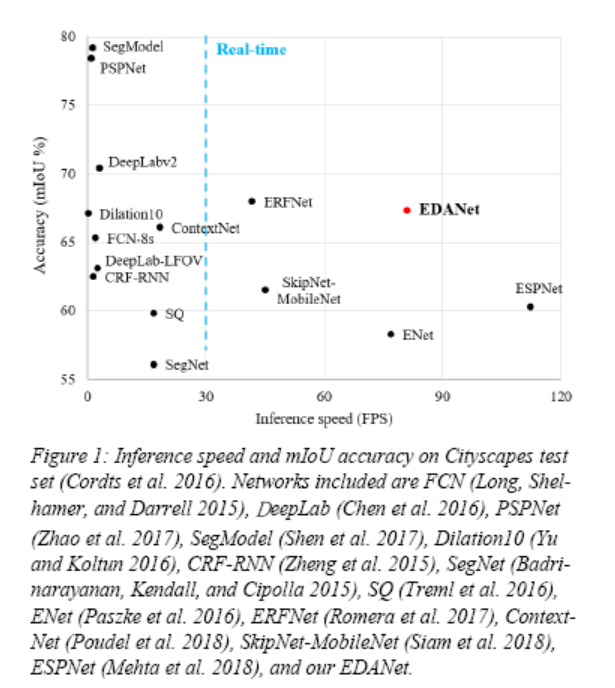
EDANet consists of several key components: asymmetric convolution, the densely connected structure from DenseNet, and dilated convolution.
- Asymmetric convolution: Splits an nxn convolution into 1xn and nx1 convolutions, reducing the number of parameters with only a slight performance drop.
- Densely connected structure: Originating from DenseNet, initially designed for image classification, but its multi-layer feature fusion is very useful for segmentation tasks.
- Dilated convolution: Increases the receptive field.
To balance efficiency and accuracy, no decoder structure, context module, or post-processing scheme was added.
2. Related Work
CNNs were initially used for image classification tasks. FCN was the first network to apply CNNs to semantic segmentation, replacing the FC layers in VGG with convolutional layers for pixel-level semantic segmentation, marking the beginning of CNN-based semantic segmentation.
In high-accuracy networks, UNet uses an encoder-decoder structure to gather spatial information from shallow network layers to enhance deeper information. DeconvNet proposed a symmetric encoder to upsample the encoder’s output, but such networks have high computational demands due to the extensive decoder. Dilation10 stacked dilated convolution layers with gradually increasing dilation rates, creating a context module to aggregate multi-scale contextual information. Deeplab introduced an ASPP module using multiple parallel dilated kernels to explore multi-scale expressions. Both modules require significant computation and inference time, making them impractical.
In high-efficiency networks, ENet was the first network aimed at real-time semantic segmentation, inheriting the ResNet structure and trimming the number of convolutions to reduce computation. ESPNet used a 1x1 convolution before the spatial pyramid to reduce computation. Both are efficient but not highly accurate.
For densely connected network structures, DenseNet achieved excellent results in image classification tasks. Some tasks have used DenseNet for semantic segmentation, with FC-DenseNet using DenseNet as an encoder and building an additional decoder structure. SDN used DenseNet as a backbone, combining it with stacked deconv structures. This method made simple improvements to DenseNet without additional optimization, increasing computation and time.
Here, asymmetric convolution is used to reduce parameters and computation, and the dense connection concept is applied to the network’s structure design. EDANet maintains high accuracy while achieving high inference speed.
3. Method
The overall network structure is as follows: 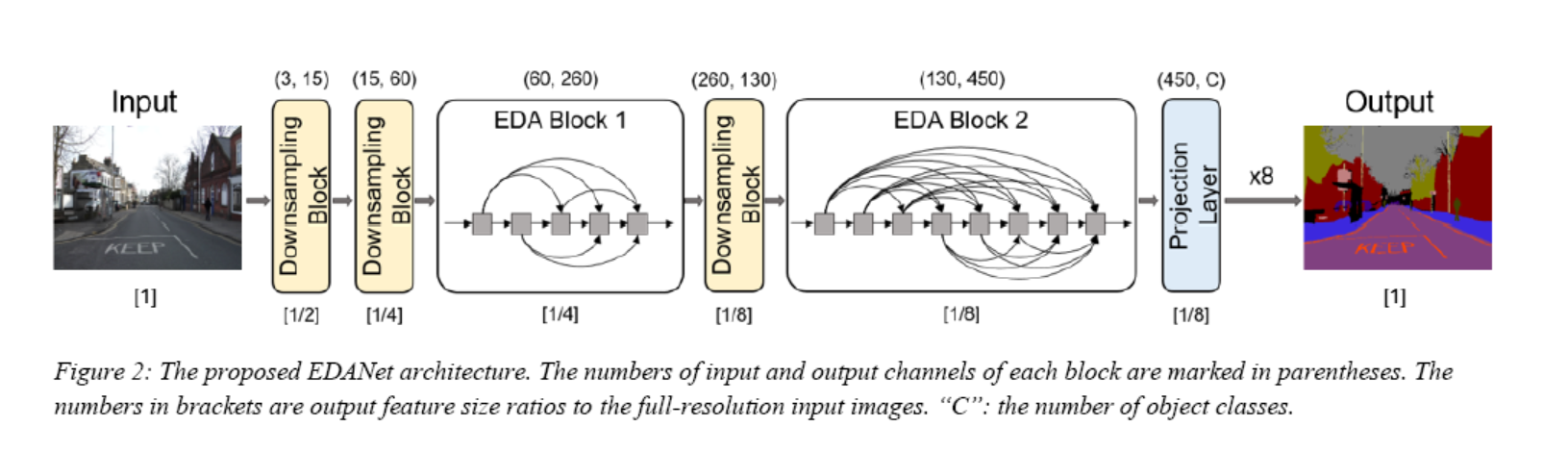
It mainly consists of several modules: Downsampling Block, EDA Block, and the final Projection Layer. The EDA Block includes multiple EDA modules. The structure of an EDA module is shown below: 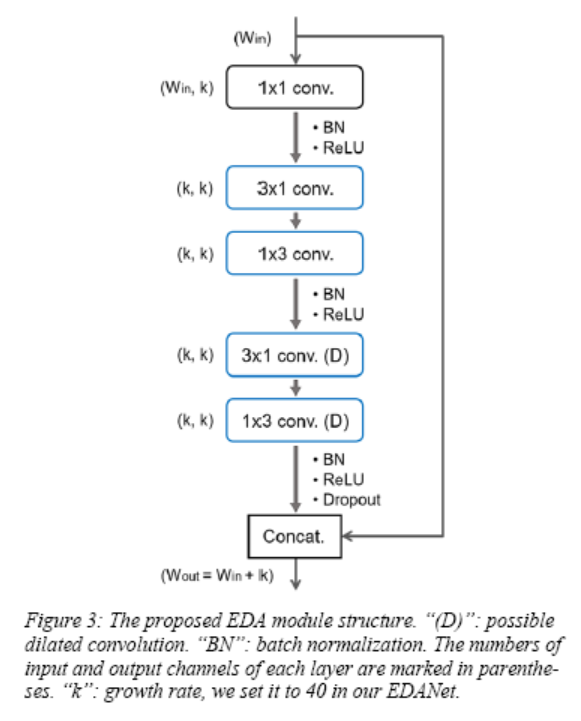
There are two sets of asymmetric convolutions, with the first set being normal convolutions and the second set being dilated convolutions. This asymmetric convolution reduces computation by 33% with only a slight performance drop.
Another technique is the connection method from DenseNet, concatenating newly learned features with the input, i.e., , where m is the m-th module. This connection structure significantly improves processing efficiency. It is well-known that deeper layers have larger receptive fields; for example, stacking two 3x3 convolutions is equivalent to a 5x5 receptive field. Dense connections allow concatenation of features from modules with different receptive fields, enabling the network to gather more information, resulting in better segmentation outcomes with low computation.
For network structure design, ENet’s initial block is used as the downsampling block, divided into two modes as shown: 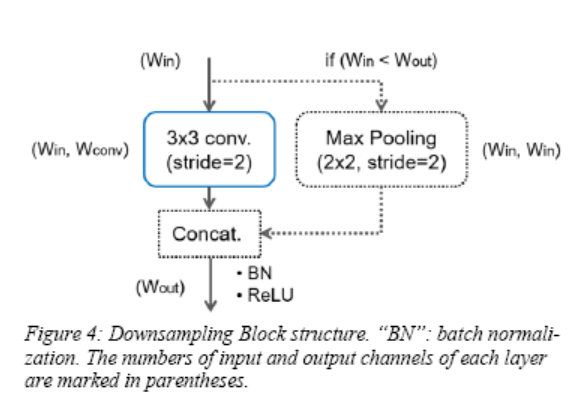
This downsampling block allows the network to have a larger receptive field for gathering contextual information. However, reducing the resolution of feature maps loses some details, which is detrimental to pixel segmentation. Therefore, only three downsampling blocks are used. In the end, relative to the full-resolution input image, the feature size becomes 1/8, whereas other networks like SegNet reduce it to 1/32.
For computational speed, no decoder is used; instead, a 1x1 convolution is added as a projection layer, using bilinear interpolation to resize the image back to full resolution. This slightly reduces accuracy but saves significant computation.
A post-activation method is used, following the conv-bn-relu order, applied to all convolution layers. During training, a 0.02 dropout is added for regularization.
4. Experiment
The focus here is on experiments conducted on Cityscapes. During training, images are downsampled to 512x1024 for training, and during validation, the output features are upsampled to the original size of 1024x2048 using bilinear interpolation. Some training details are omitted here, EDANet training details. The final experimental results are divided into two parts: results from the ablation study and results comparing EDANet with other network structures on Cityscapes.
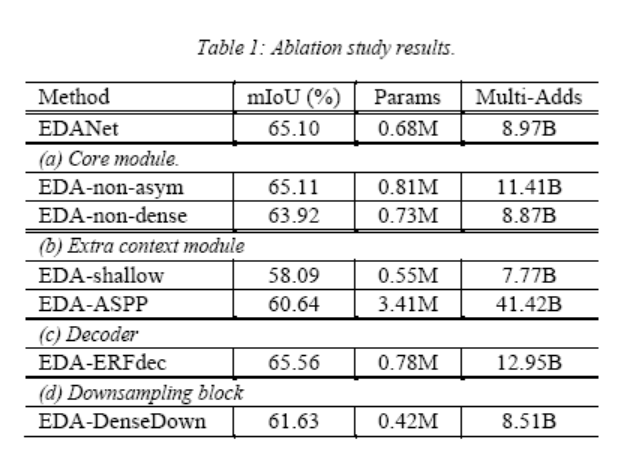
Comparison of experimental results on Cityscapes with other networks: