InceptionV4 Summary
Abstract
In recent years, very deep convolutional neural networks have played a significant role in enhancing image recognition performance. The Inception network structure not only offers excellent performance but also maintains relatively low computational costs. The combination of recent residual connections with traditional structures achieved the best results at the 2015 ILSVRC, comparable to InceptionV3. Considering the integration of Inception networks with residual connections, there is ample evidence that residual connections can significantly accelerate the training of Inception networks. There is also evidence that Inception networks with residual connections slightly outperform those without, even with almost the same computational load. This paper also introduces some new Inception networks with and without residual connections, which have also significantly improved the single-frame classification performance of the 2012 ILSVRC. Finally, it is mentioned that using appropriate activation scaling can make the training of very wide residual Inception networks more stable.
1. Introduction
AlexNet achieved great success in CV tasks in 2012, and deep CNNs have been successfully applied in various CV fields. Since residual connections are crucial for training deep structures, this paper combines residual connections with deep Inception networks, thus reaping all the benefits of residual connections while maintaining computational load.
Besides direct integration, this paper explores whether making Inception deeper and wider can achieve better performance. Therefore, InceptionV4 was designed, and due to TensorFlow’s distributed computing technology, there is no longer a need to partition the model.
This paper also compares Inception-V3, Inception-V4, and residual Inception networks with similar computational costs. It is evident that InceptionV4 and Inception-ResNet-V2 have similar single-frame performance on the ImageNet validation set, both surpassing state-of-the-art results. Finally, it was found that this integrated performance has not yet reached the level of classification noise on the dataset, indicating room for improvement.
2. Related Work
CNNs have become popular in large-scale image recognition tasks, with Network in Network, VGGNet, and GoogLeNet (InceptionV1) being important milestones. He provided ample theoretical and practical explanations of the advantages of residual connections, especially in detection applications. The author emphasizes that residual connections are inherently necessary for training very deep CNN models, but our findings do not support this view, at least not in the context of image recognition. This likely requires more arguments and understanding of the role of residual connections in deep networks. The experimental section demonstrates that even without residual connections, it is not difficult to train very deep networks, although residual connections can significantly improve training speed, which is an important point for their use.
Starting from InceptionV1, the network structure has undergone multiple improvements, achieving V2 by introducing BN and V3 through additional factorization.
3. Architectural Choices
This section mainly introduces the specific structure of the network.
In the residual version of the Inception network, a simpler Inception block is used, with a 1x1 convolution following each Inception block to compensate for changes in channel numbers. Another minor difference between the Inception and residual versions is that in the residual version, BN is only used at the top of traditional layers and not at the top of summations. This is a compromise to allow the network to have more Inception blocks and be trainable on a single GPU. In fact, using BN throughout would be more beneficial.
When filters exceed 1000, the network fails early in training, and reducing the learning rate or adding extra BN cannot prevent this phenomenon. He proposed using a low learning rate warm-up followed by high learning rate training to improve this issue. However, this paper finds that scaling the residuals can more reliably solve this problem without losing accuracy and can make training more stable.
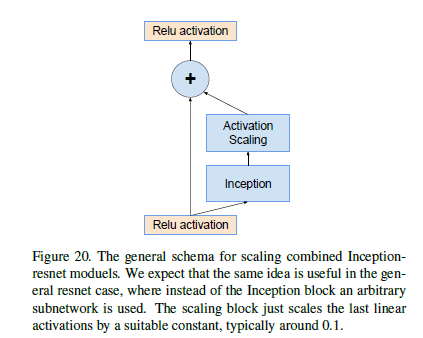
4. Training Methodology
This section mainly introduces some training details, using the TensorFlow distributed computing framework, with Nvidia’s Kepler GPUs. The best model uses the RMSProp algorithm, decay=0.9, , with a learning rate of 0.045, decaying at an exponential rate of 0.94 every two epochs.