Learning to Push by Grasping: Using Multiple Tasks for Effective Learning
Abstract
Currently, end-to-end learning frameworks have become popular in the field of robotic control. These frameworks take state/images as direct input and output predicted torque and action parameters. However, they have been criticized for their high data demands, leading to discussions about their scalability—specifically, whether end-to-end learning requires a separate model for each task. Intuitively, sharing between tasks is beneficial, as they all require some common understanding of the environment. This paper explores the next step in data-driven end-to-end learning frameworks: moving from task-specific models to joint models for multiple robotic tasks. Surprisingly, it finds that multi-task learning performs better than single-task learning with the same amount of data. For instance, a model trained with 2.5k grasp data and 2.5k push data outperforms a model trained with 5k grasp data alone.
1. Introduction
When a robot is about to perform an operation (such as grasping), it needs to complete several steps: (a) infer the properties of the object, (b) have some understanding of its own structure, and (c) understand what constitutes a successful grasp and how to achieve it. Many analytical frameworks define (c) mathematically and rely on additional perception modules for the sensing part, often simplifying it to some extent. This over-reliance has led to suboptimal results. End-to-end models learn a joint model of (a)-(c) in a data-driven manner, showing promising results.
Despite the success of end-to-end models, they have faced criticism, mainly because they require a separate model for each task, with each model needing a large amount of data for training. Is there a way to share between tasks to reduce the data demand? Intuitively, there is, because all tasks require parts (a) and (b). For example, push task data can help train the perception module for grasp tasks.
As previously mentioned, combining data from different tasks with the same data volume performs better than data from a single task. This might be because performing multiple tasks allows exploration of target properties and patterns not accessible in the original task, acting as a form of regularization and enabling learning of more generalized features.
2. Related Work
Grasping is an older problem, with earlier methods mostly based on analytical approaches and 3D reasoning to predict grasp positions and configurations. Recently, data-driven learning methods have emerged. Pushing is another fundamental robotic task, allowing movement of target objects without grasping. We also use tactile sensing prediction (poking) as an auxiliary task for learning pushing and grasping.
Previous work mentioned that collecting large amounts of data can be used for robotic tasks, but data collection is a time-intensive task. Multi-task learning (MTL) uses a shared approach to explore commonalities between these tasks, initializing current parameters with previous tasks. This paper focuses on exploring end-to-end MTL models for grasping and pushing.
For robotic tasks, previous frameworks were mainly task-specific. This is the first report showing that sharing between multiple tasks can improve task performance, and it finds that the value of additional data points from the original task is not as significant as that of alternate tasks. This is likely because such sharing enhances robustness and regularizes feature learning, improving multiple tasks. Through exploring MTL, we find that even with a small amount of data, efficient models can be obtained by leveraging large amounts of data from other tasks.
3. Overview
Our goal is to explore whether data collected for specific tasks can be used for other tasks. Current research focuses on training a specific model for each task. However, we believe most of these problems require learning how the world works, allowing for data sharing to accelerate learning. Specifically, some parameters in CNNs correspond to visual features, some to underlying structures and physics, some to the robot’s structure and control information, and the remaining parameters are task-specific. If this is the case, data sharing between tasks is crucial.
This paper investigates whether multi-task learning can yield a better control model for grasping and pushing. We collected data for grasping, pushing, and poking tasks and explored the performance of Grasp ConvNet using only grasping data versus using a combination of grasping, pushing, and poking data. A similar comparison was made for Push ConvNet.
4. Approach
Here, we formally describe the three tasks: planar grasping, planar pushing, and the application of poking data in the framework.
A. Planar Grasps
A grasp can be defined by three parameters , representing the grasp point and coordinates. The training data includes 37k failure data and 3k success data, while the test data has 2.8k failure data and 0.2k success data.  A grasp problem can be defined as predicting a successful grasp configuration from an input image. However, this problem is ill-posed because an object can have multiple possible grasp positions. Therefore, a batch of images was sampled with at the center of the image, requiring only the prediction of the grasp angle. The angle is classified into , converting the problem into 18 binary classification problems, as the evaluation criterion is binary: grasp success or failure.
A grasp problem can be defined as predicting a successful grasp configuration from an input image. However, this problem is ill-posed because an object can have multiple possible grasp positions. Therefore, a batch of images was sampled with at the center of the image, requiring only the prediction of the grasp angle. The angle is classified into , converting the problem into 18 binary classification problems, as the evaluation criterion is binary: grasp success or failure.
B. Planar Push
Each push data point includes three parts: initial image , final image , and action . The entire dataset includes 5k actions and 70 objects. 
The task for the push learner is to predict the push action given the initial and final images. A siamese network with shared weights is used, with as input on one side and on the other. After processing both sides, they are concatenated, and a fully connected layer outputs . The loss function used is the Euclidean distance.
C. Planar Poke
This dataset includes the target image and the feedback sensed during poking. The learner’s task is to predict from the input image. 
Two parameters represent : the slope and intercept of the voltage increase. A structure similar to grasping is used, sharing the first three layers of network parameters with grasping, while the remaining network is dedicated to the poking task. The loss function is also the Euclidean distance.
D. Network Architecture
Feature transfer here has two forms: poking+pushing->grasping and poking+grasping->pushing. The network architecture is shown below. 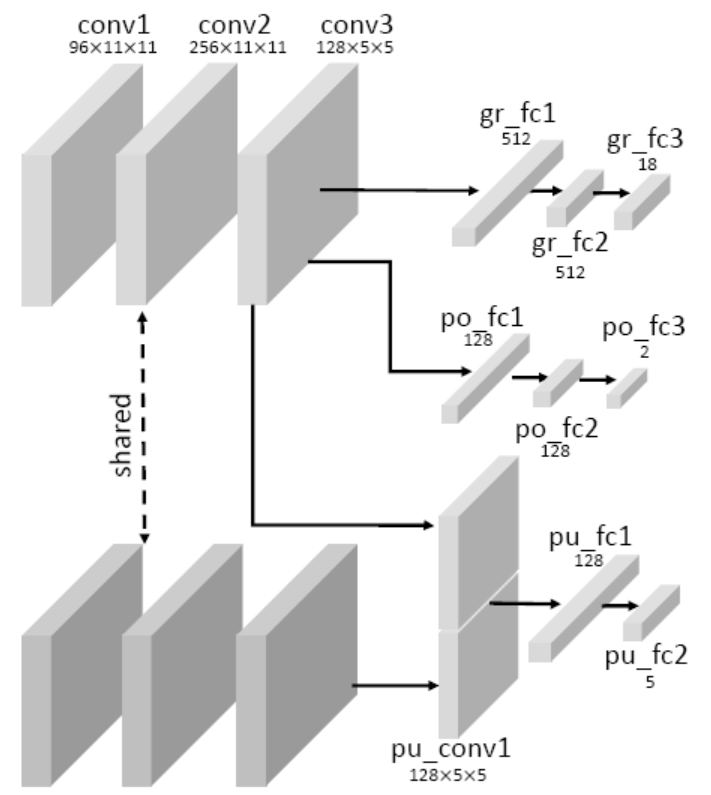
In the first three conv layers, the top and bottom layers share weights. The numbers on the conv layers represent the size and number of convolution kernels. Each conv layer is followed by BN and ReLU. For the grasp task, the first two fc layers are followed by dropout layers with p=0.5 and ReLU, as is the case for poking. For the pushing task, since two images are input, two convolution processes are used as shown, but the parameters are shared. After concatenation, the same fc layers are used to output the predicted 5-dimensional vector .
E. Training
This section mainly introduces training details. For the loss function, grasping uses cross-entropy, while pushing and poking use Euclidean distance.
For the entire joint training process, batch_size=128 is used to obtain batches for the three tasks. The gradient calculation for fully connected layers is the same as in normal cases, while the gradient calculation for shared conv layers is slightly different, with the formula:
where are the loss functions for grasping, pushing, and poking tasks, respectively. The RMSProp algorithm, a gradient descent-based algorithm, is used during training, with a learning rate of 0.002, momentum=0.9, decay=0.9, and the learning rate decaying by a factor of 0.1 every 5000 steps.
5. Results
During validation, classification error is used for the grasping task, and mean square error is used for the pushing task.
A. Evaluating Multi-Task vs. Task-Specific
This section compares the performance of multi-task training and task-specific training. Here, multi-task ignores the poking case, with training data equally split between pushing and grasping. The conclusion is that with small data volumes, task-specific data performs better, while with large data volumes, multi-task performs better. This may be because multi-task data provides diversity, acting as a regularization effect to prevent overfitting. 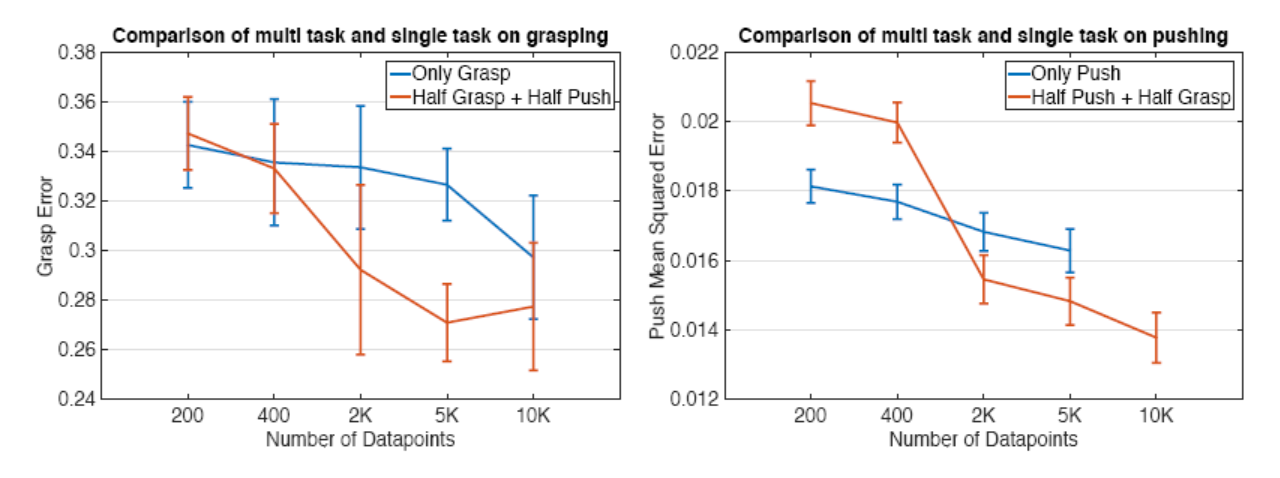
B. Multitask: Data Ratio
This section experiments with the size of data proportions. The results are shown below, indicating that pushing is more easily transferable than grasping. 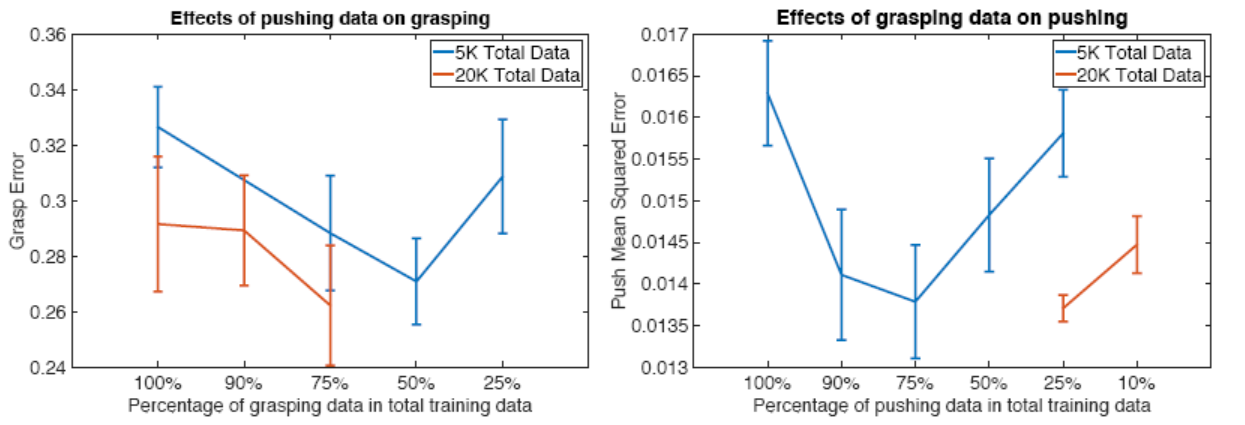
C. Multitask: 3-task performance
This section verifies the impact of including poking and experiments with different data ratios, showing that poking is quite useful. The results are shown below. 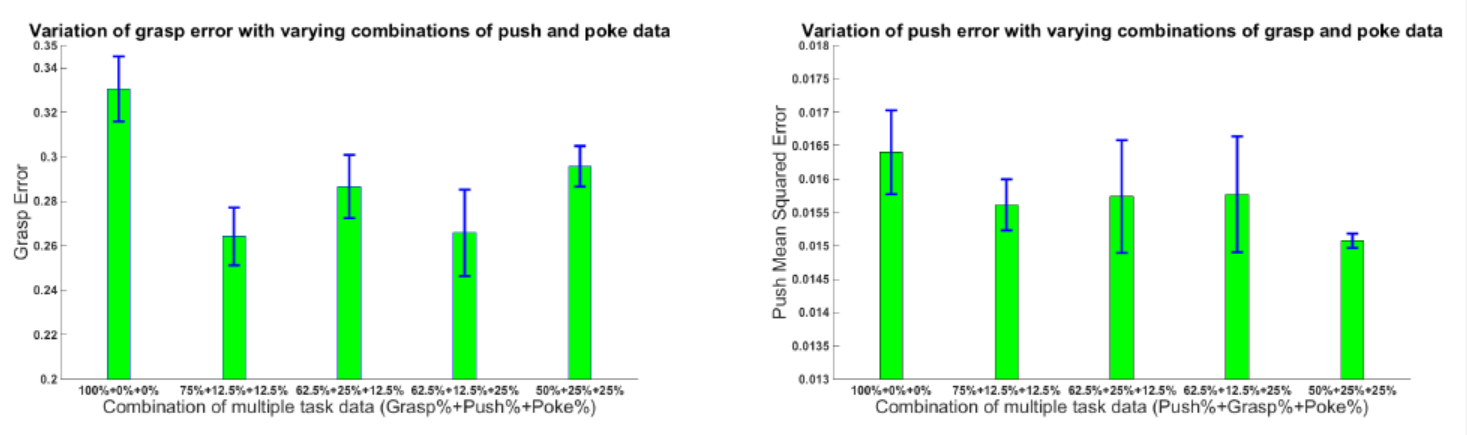
6. Discussion
The current research trend focuses on task-specific learning, with many discussions suggesting that multi-task learning is not useful. However, this creates an issue: end-to-end learning requires a large amount of training data. This paper demonstrates that multi-task training is not only feasible but also achieves better results with the same data volume. We hypothesize that this is due to the diversity of data providing a regularization effect. This paper opens a new subfield in robotics for multi-task learning, especially in sharing between different tasks.