MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Abstract
针对移动和嵌入式视觉应用,本文提出了一种高效的模型称之为MobileNets,基于depthwise separable convolutions构造的一种轻量级神经网络。该模型使用两个超参数来平衡准确率和延迟,并针对二者的平衡在ImageNet上做了广泛的实验,与其他模型相比展现出了强大的性能。并通过实验展现了ImageNet在各种应用上的强大之处,包括目标检测,精细化分类,人脸属性和大范围地理定位等。
1-Introduction
自从AlexNet使深度CNN变得流行起来,CNN在计算机视觉方面变得无所不在,总体趋势在于发明更深更复杂的网络来实现更高的精度。然而这些改进在网络速度和尺寸上并没有起到促进作用,显示应用中的机器人,无人驾驶汽车,AR等都需要在有限的计算平台下具有实时性。
本文提出了一种高效的网络结构和两个超参数构成的集合来构建用于以上应用的模型,章节2审视了前人在构建小型模型方面的经验,章节3描述了MobileNet的结构和宽度乘子,分辨率乘子这两个超参数,章节4描述了其在ImageNet和各种应用下的实验,最后章节5进行了总结。
2-Prior Work
构建高效的小尺寸网络在最近很流行,很多方法能被分类成两种:压缩欲训练网络或者直接训练小尺寸网络,本文提出的网络结构可以让搭建者来选择满足资源约束的小尺寸网络,MobileNet主要专注于优化延迟并产出小尺寸网络,许多网络都只考虑了尺寸而没有速度。
MobileNets利用depthwise separable convolutions,Inception model也利用这个来减少前几层的计算量。Flattened networks利用全分解卷积来构建网络,并且展现了分解网络的潜力。Factorized networks利用了相似的卷积分解,也利用了topological connections。另外的还有Xception network:通过缩放depthwise separable filters。Squeezenet:利用bottleneck。其他一些减少计算量的网络:structured transform network,deep fried convnets。
获得小尺寸网络的其他方法:对于欲训练网络的shrinking,factorizing,compressing,其中compressing包含:product quantization,hashing,pruning,vector quantization,Huffman coding。其中factorization的方法:[14,20]文献。另外的方法还有distillation(用大网络的输出来训练小网络),low bit networks。
3-MobileNet Architecture
这一章首先介绍核心的depthwise separable filters,然后介绍MobileNet的网络结构,最后以shrinking的两个超参数(宽度乘子,分辨率乘子)的介绍结尾。
3.1-Depthwise Separable Convolutions
depthwise separable convolution是将一个标准卷积分成了两部分:depthwise convolution和1x1的卷积。同时也将一个卷积层分成了两层:filtering和combining。这样的分解可以极大地减少计算量和模型尺寸。标准卷积和depthwise separable convolution的对比如下图: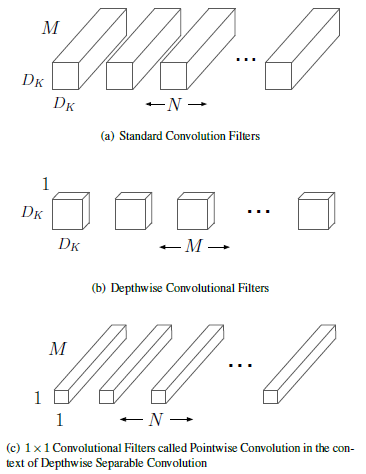
对于一个标准卷积,假设其输入维度为,输出维度为,卷积核的维度为,那么在stride=1,padding的情况下,标准卷积的计算公式为:
标准卷积的计算消耗为:
而depthwise separable convolution的计算消耗为:
前者为depthwise convolution的计算消耗,而后者为1x1的卷积的计算消耗,通过比较,二者的计算量之间的减少为:
如果使用3x3的卷积核,那么计算量将减小8-9倍,并且在准确率上只有微小的降低。再进一步进行分解[16,31]并不会减少很多计算量因为depthwise convolution的计算量已经很小了。
3.2-Network Structure and Training
MobileNet除了第一层是标准卷积之外,其余结构都是基于depthwise separable convolution来构建的。整个网络结构如下图: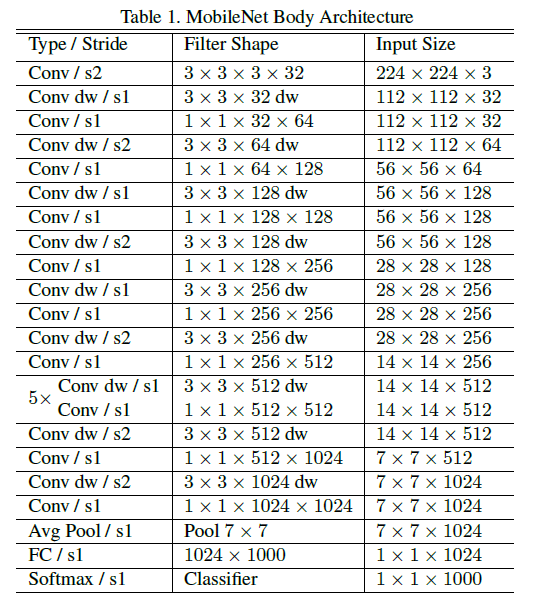
值得一提的是,并不能以小数量的Mult-Adds就认为这个模型是高效的。让这些Mult-Adds操作能够高效实现同样也很重要。比如非结构化的稀疏矩阵操作并不一定比密集矩阵的操作更快,除非具有很高的稀疏度。我们的模型几乎将所有的计算转化为密集的1x1卷积操作,这种操作可以用一种经过高度优化的通用矩阵乘法(GEMM)来实现。通常的用GEMM实现的卷积操作需要先使用im2col来对输入在内存中重新进行排序,例如这样的操作可以用Caffe来实现。而我们的1x1卷积则不需要先排序,可以直接应用GEMM算法(最优的数值线性代数算法之一)。在MobileNet中,95%的Mult-Adds操作和75%的参数都来自1x1卷积。
对于训练的细节:TensorFlow+RMSprop+asynchronous gradient descent(类似InceptionV3)+更少的正则化和数据增强(小模型不容易过拟合)+很少或者没有weight decay on the depthwise filters(因为里面已经只有很少的参数)
3.3-Width Multiplier: Thinner Models
尽管当前的MobileNet已经很小很快了,不过有时候还需要更小的模型,我们引入一个超参数(width multiplier)来构建这些更小的模型,这个参数的目标是均匀的在每一层来让整个网络变得更加瘦小。给定一个,则让输入通道数M变为,输出通道数N变为,的取值通常为1,0.75,0.5,0.25,使用了该参数之后的计算量为:
计算量大约变成了以前的
3.4-Resolution Multiplier: Reduced Representation
第二个减少网络计算量的超参数是(resolution multiplier), 通过设置输入的分辨率来设置这一参数,然后内部的分辨率也会随之减少,在加上了超参数之后的计算量则变为:
通常设定之后的分辨率为224,192,160,128。注意在设定该参数之后计算量会发生变化,但是模型参数则不会发生变化。
4-Experiments
这部分主要讲了一些实验,首先是depthwise separable convolution,标准卷积的对比,瘦小和浅层MobileNet的对比。然后介绍了两个超参数的实验结果,包括ImageNet的准确度,Multi-Adds操作的数量和参数的数量。最后介绍了MobileNet在其它一些不同应用上(精细化分类,大尺度地理定位,人脸属性,目标检测,人脸嵌入)的实验结果。
4.1-Model Choices
试验结果表明,全卷积的MobileNet和depthwise separable convolution相比,精度差不多,但是depthwise separable convolution的参数和计算量相比而言小了很多。瘦小和浅层MobileNet相比,计算量差不多的情况下瘦小MobileNet精度更高一些。实验结果如图: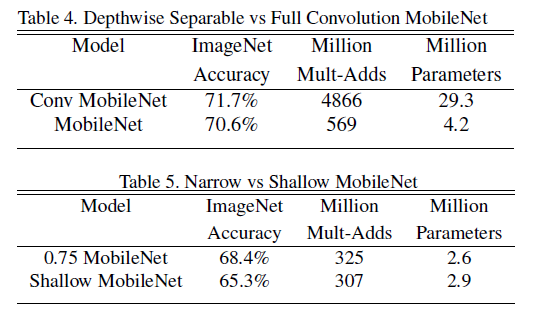
4.2-Model Shrinking Hyperparameters
这一部分是讲关于上述两个超参数调参的,其实验结果如下图所示: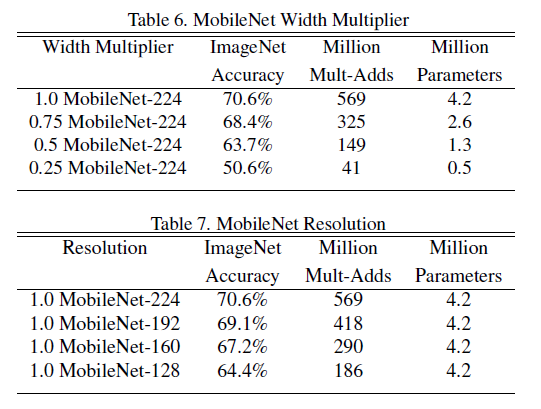
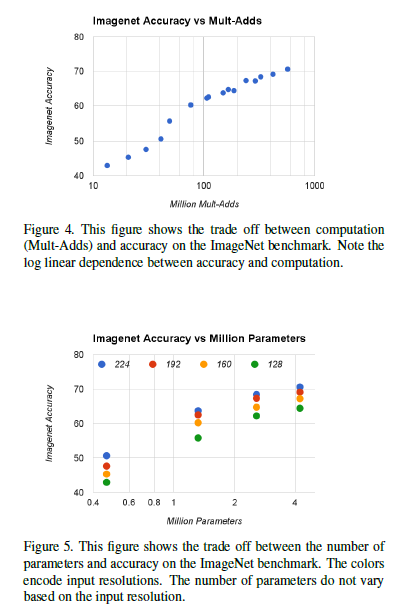
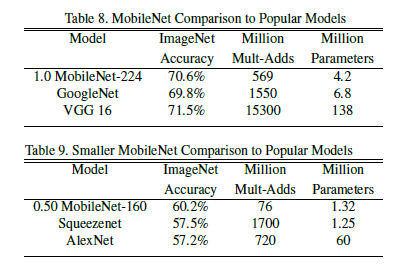
4.3-Fine Grained Recognition
利用Stanford Dogs dataset数据集和网上的一些包含噪声的数据上训练了应用于精细化分类的模型,并且进行了很好的调参,最后在减小计算量和模型尺寸的情况下得到了近似于state of the art的结果,实验结果如图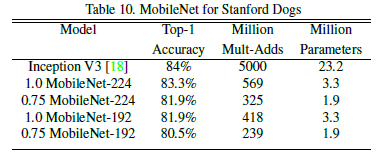
4.4-Large Scale Geolocalizaton
PlaNet是将这个定位问题转化为一个分类问题来解决,PlaNet已经成功定位了很多照片,并且在这个问题上的表现已经超过了Im2GPS,用MobileNet结构在同样的数据下重新训练了PlaNet,实验结果如下图: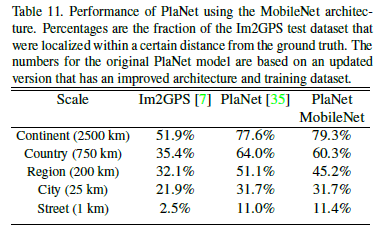
4.5-Face Attributes
MobileNet还能够用于压缩未知训练过程的大规模系统,在人脸属性分类系统中使用了MobileNet和distillation的协同作用,在将二者进行结合之后,系统不仅不需要进行正则化,而且表现出来了更强的性能,实验结果如下图: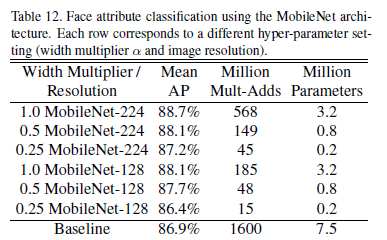
4.6-Object Detection
这个实验利用VGG,Inception,MobileNet在SSD和Faster-RCNN上对COCO数据集进行了训练,结果如下图: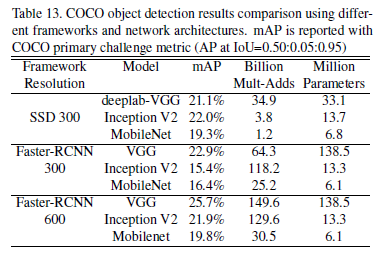
4.7-Face Embeddings
FaceNet是FaceEmbedding的state of the art结果,这里同样的利用distillation来训练Mobile FaceNet。结果如下图: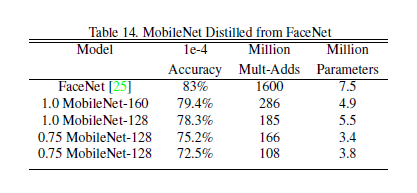
5-Conclusion
提出了基于depthwise separable convolution的模型结构,并且使用了width multiplier和resolution multiplier两个超参数来控制模型的复杂度,并且在模型尺寸,速度,准确度上面与其他模型进行了对比,证明了MobileNet在多种应用之下的高效性,下一步打算对MobileNet进行改进和进一步开发。
6-其他的一些相关总结
数据集:ImageNet(图像分类),Stanford Dogs dataset(精细化分类),YFCC100M(人脸属性),COCO(目标检测)
相关的论文:
数据集
《Imagenet large scale visual recognition challenge》(ImageNet,ILSVRC 2012)
《In First Workshop on Fine-Grained Visual Categorization》(Stanford Dogs dataset)
《Yfcc100m: The new data in multimedia research》(YFCC100M)
更深更复杂精度更高的神经网络
《Inception-v4,inception-resnet and the impact of residual connections onlearning》(InceptionV4)
《Rethinking the inception architecture for computer vision》(InceptionV3,空间维度的额外分解)
《Deep residual learning for image recognition》(resnet)
《Going deeper with convolutions》(GoogleNet)
《Very deep convolutional networks for large-scale image recognition》(VGG16)
《Imagenet classification with deep convolutional neural networks》(AlexNet)
神经网络的压缩加速
《Flattened convolutional neural networks for feedforward acceleration》(空间维度的额外分解)
《Factorized convolutional neural networks》(对卷积进行分解)
《Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 1mb model size》(利用bottleneck来实现小型网络)
《Quantized convolutional neural networks for mobile devices》(基于product quantization进行压缩)
《Xnornet:Imagenet classification using binary convolutional neural networks》(利用low bit networks)
《Training deep neural networks with low precision multiplications》(利用low bit networks)
《Quantized neural networks: Training neural networks with low precision weights and activations》(利用low bit networks)
《Xception: Deep learning with depthwise separable convolutions》(缩放depthwise separable filters)
《Structured transforms for small-footprint deep learning》(用于减少计算量的网络)
《Deep fried convnets》(用于减少计算量的网络)
《Compressing neural networks with the hashing trick》(利用哈希来压缩神经网络)
《Rigid-motion scattering for image classification》(最初提出标准卷积分解为depthwise conv和1x1 conv)
《Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding》(利用哈夫曼编码压缩网络)
《Speeding up convolutional neural networks with low rank expansions》(额外的变量分解)
《Speeding-up convolutional neural networks using fine-tuned cp-decomposition》(额外的变量分解)
《Distilling the knowledge in a neural network》(利用distillation来从大型网络训练小网络,以进行压缩)
BN
《Batch normalization: Accelerating deep network training by reducing internal covariate shift》(InceptionV2也从此而来)
框架
《Caffe: Convolutional architecture for fast feature embedding》
《Tensorflow: Large-scale machine learning on heterogeneous systems》
图像定位
《IM2GPS: estimating geographic information from a single image》(提出了Im2GPS)
《Large-Scale Image Geolocalization》(关于Im2GPS)
《PlaNet - Photo Geolocation with Convolutional Neural Networks》(PlaNet)
精细化分类
《The unreasonable effectiveness of noisy data for fine-grained recognition》
目标检测
《Faster r-cnn: Towards real-time object detection with region proposal networks》(Faster-RCNN框架)
《Ssd: Single shot multibox detector》(SSD框架)
人脸嵌入
《Facenet: A unified embedding for face recognition and clustering》(FaceNet,基于三元损失来构建人脸嵌入)