Knowledge Distillation: Teaching a Small Network to Mimic a Big One
Knowledge distillation is a common technique for raising training accuracy and speeding up convergence, often used to fine-tune models after compression and to train the small networks inside NAS.
The idea is straightforward: take a high-accuracy teacher model’s outputs as labels for a student model, and have the student mimic the teacher’s behavior.
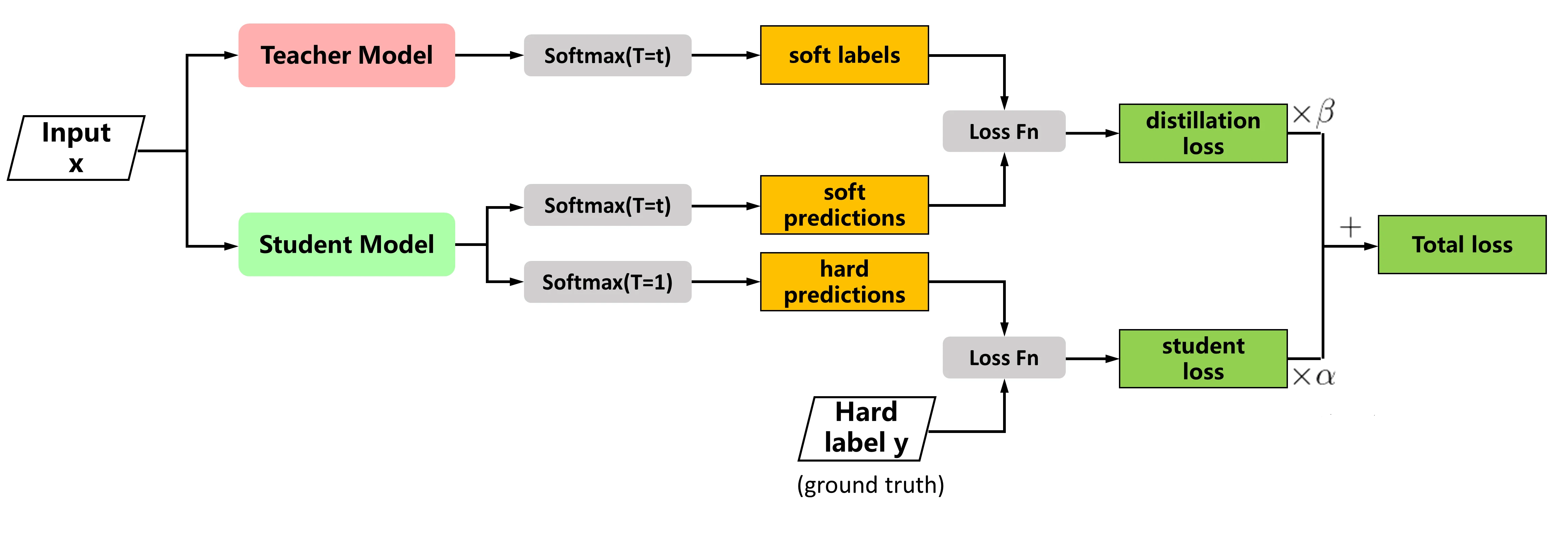
Classic distillation: soft labels and temperature
The most common implementation adds the student’s own classification loss to a distillation loss between teacher and student outputs. Let be cross-entropy, the softmax temperature, the student’s logits and the teacher’s, the label, and the two loss weights:
The first term is the student’s ordinary loss against the true label; the second pulls the student’s soft output toward the teacher’s. The temperature-scaled softmax is:
At this is the usual softmax; smooths the class distribution, making it easier for the student to imitate — the soft labels and soft predictions in the figure above.
Distilling at intermediate layers: FitNets and FSP
Beyond transferring knowledge at the final output, FitNets proposes hints training: transferring knowledge between an intermediate layer of the teacher and the student, giving the student “hints.”
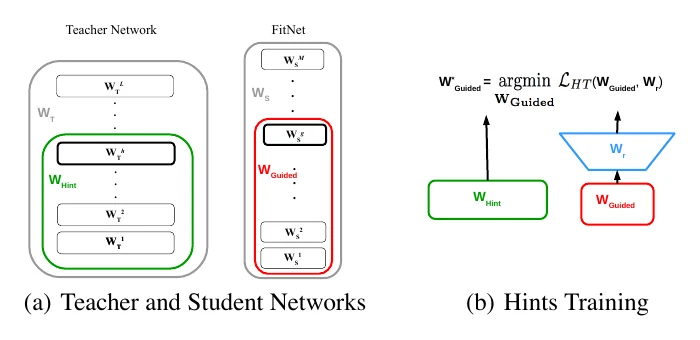
The hint loss is below, where is an extra layer to match dimensions (with parameters ), and , are the teacher’s and student’s intermediate outputs:
After hints training, you still finish training the whole student via output-layer distillation.
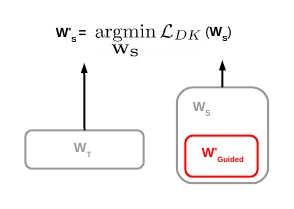
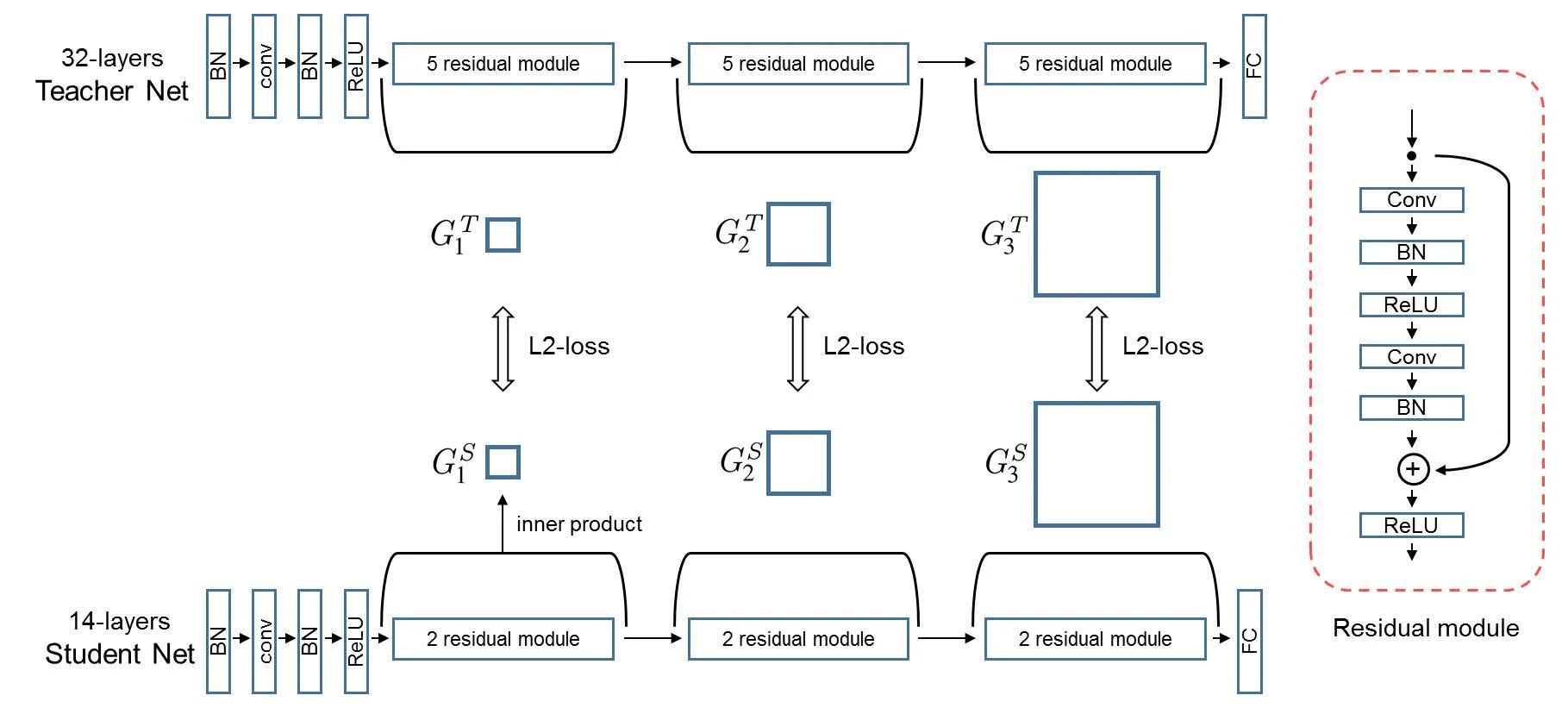
Another work (A Gift from Knowledge Distillation) transfers knowledge via the FSP matrix — each element is the inner product between two layers’ feature maps.
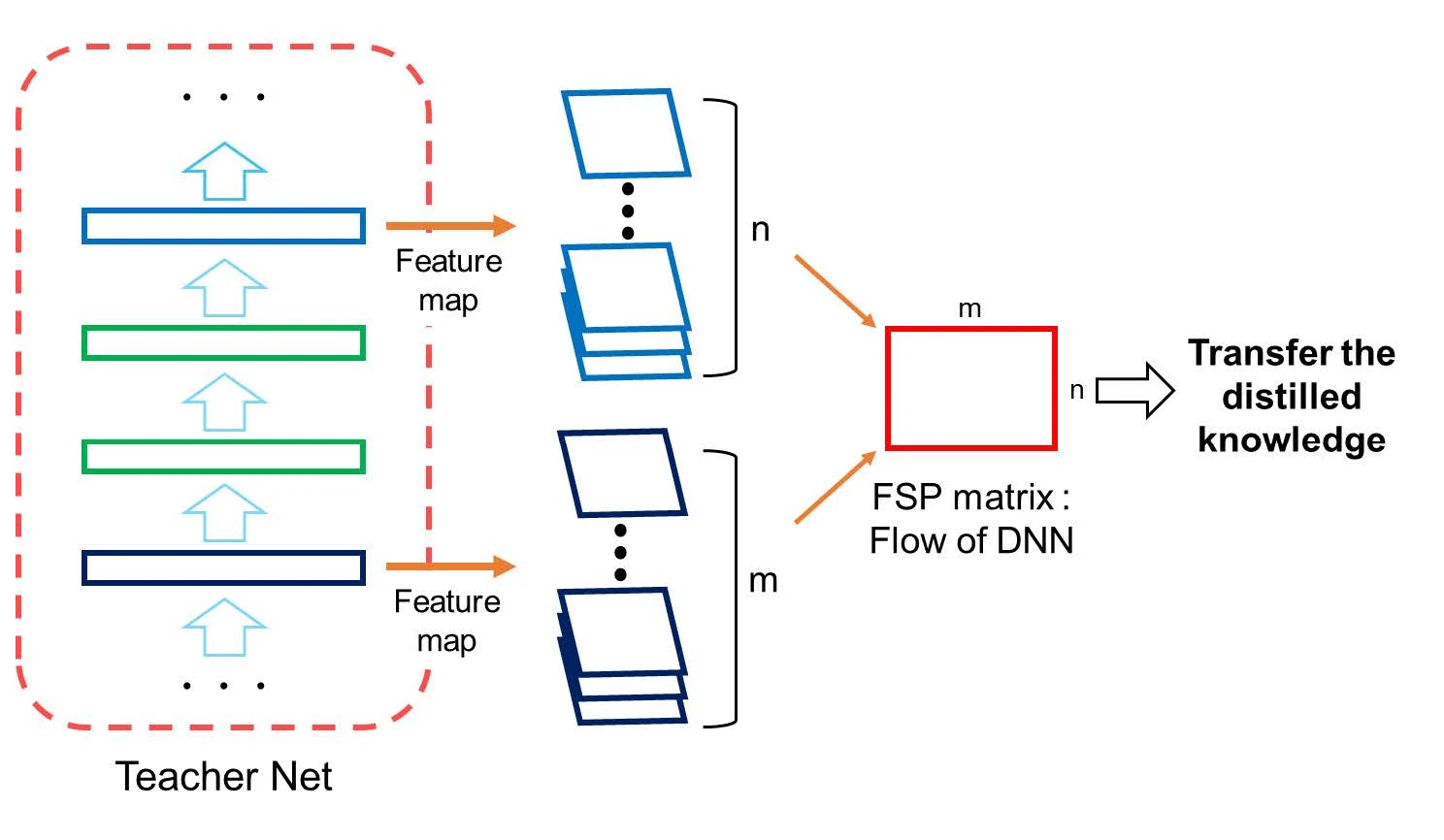
Like FitNets it transfers at intermediate layers, but across multiple layers (not just one). It suits cases where teacher and student have similar structure but different depth, so the FSP matrices share dimensions and an L2 loss can be computed.
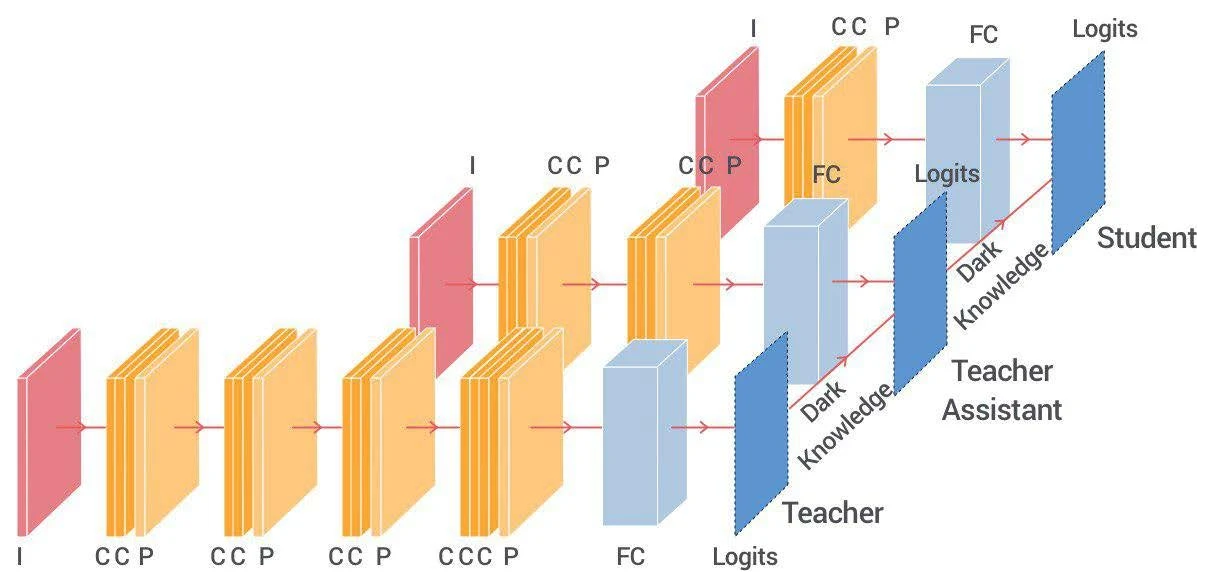
Teacher assistant: keep the gap small
Worried that too large a gap between teacher and student makes transfer hard, TAKD inserts a teacher assistant between them: knowledge flows teacher → assistant → student, with the extra step smoothing the transfer.
Learning from each other: DML
The methods above all have the student learn one-way from the teacher. DML (Deep Mutual Learning) instead has a cohort of networks learn from one another: two differing architectures complement each other during training, each ending up better. Each network’s loss includes not only the cross-entropy against the label but also the KL divergence against the other network’s output.

The two networks’ losses , are:
where is the cross-entropy loss and is the Kullback-Leibler divergence:
References
- Hinton, Geoffrey, Vinyals, Oriol, Dean, Jeff. Distilling the Knowledge in a Neural Network. arXiv:1503.02531, 2015.
- Gou, Jianping, et al. Knowledge Distillation: A Survey. arXiv:2006.05525, 2020.
- Romero, Adriana, et al. FitNets: Hints for Thin Deep Nets. arXiv:1412.6550, 2014.
- Yim, Junho, et al. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. CVPR, 2017.
- Mirzadeh, Seyed Iman, et al. Improved Knowledge Distillation via Teacher Assistant. AAAI, 2020.
- Zhang, Ying, et al. Deep Mutual Learning. CVPR, 2018.