How Do You Measure Whether a Neural Network Is "Good" and "Fast"?
When you set out to optimize a model, the first step usually isn’t touching the network — it’s getting clear on one thing: what exactly am I optimizing, and how will I know it got better? As the saying goes, if you can not measure it, you can not improve it. So before talking about any speedup or compression, we need to unpack the word “performance.”
A neural network’s performance splits into two independent lines:
- Task performance — how well the model does on the job it’s meant to do (classification accuracy, detection mAP).
- Efficiency performance — what it costs to run, in both time (latency) and space (memory).
The goal is to push the model forward on both at once. Let’s take them in turn.
Task-oriented metrics
Most CNN applications land in computer vision, so let’s look at a few of the most common tasks — image classification, object detection, semantic segmentation, super-resolution — and the metrics each one uses.
Classification comes in single-label and multi-label flavors. Single-label classification generally reports Top-1 and Top-5 accuracy: both are “correctly classified samples / total samples,” differing only in that Top-1 requires the model’s highest-probability class to match the label, while Top-5 counts a hit if any of the five highest-probability classes matches. But accuracy isn’t differentiable, so you can’t optimize it directly; single-label classification typically uses cross-entropy loss:
where is the output probability vector (dimension = number of classes), is the label class, and is the per-class weight. Multi-label classification usually treats each label as a binary classification problem, then reduces the per-label losses to a single number by summing or averaging. Averaging, with total classes:
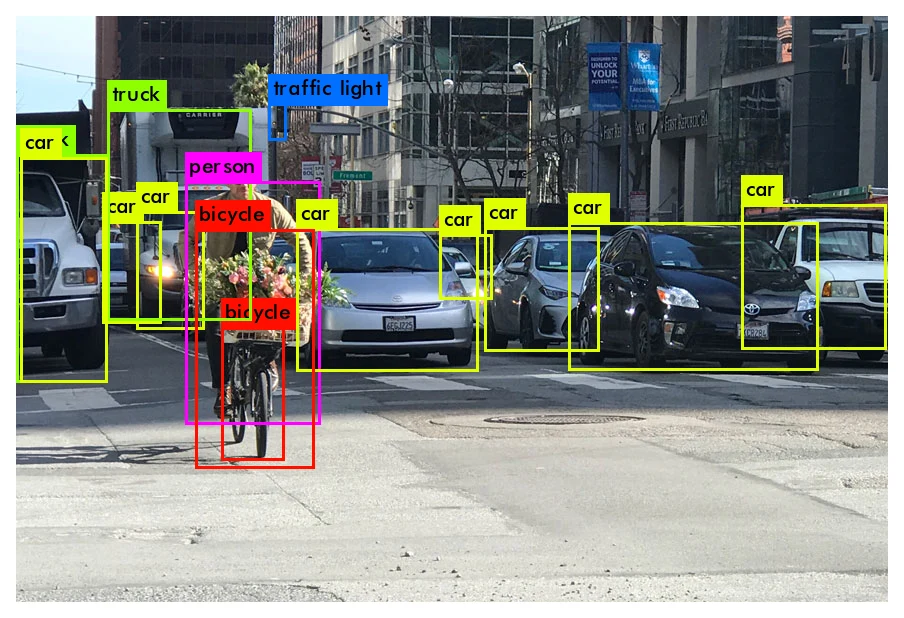
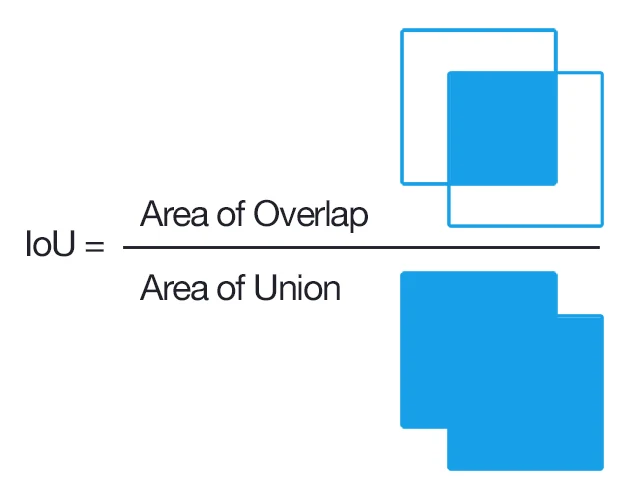
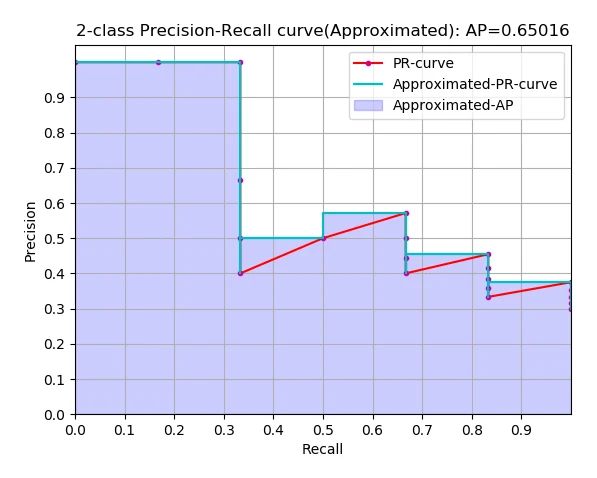
Object detection most commonly uses mAP (mean Average Precision): the mean of the per-class AP (Average Precision) values, where each class’s AP equals the area under that class’s PR curve (Precision-Recall Curve). Roughly: after the model predicts a batch of boxes over the whole dataset, for a given class you take all of its predicted boxes across all images, sort them by confidence high-to-low, then match each against the ground-truth boxes in order. If a prediction’s IoU (Intersection over Union) with some ground-truth box exceeds a threshold (usually 0.5), it’s a TP (True Positive); otherwise an FP (False Positive), and that ground-truth box is marked as detected and dropped from later matching. Sweeping the confidence threshold gives a series of TP/FP values, and from them a series of precisions and recalls:
Plotting recall on the x-axis and precision on the y-axis (with interpolation) gives the PR curve; the area under it is the AP.
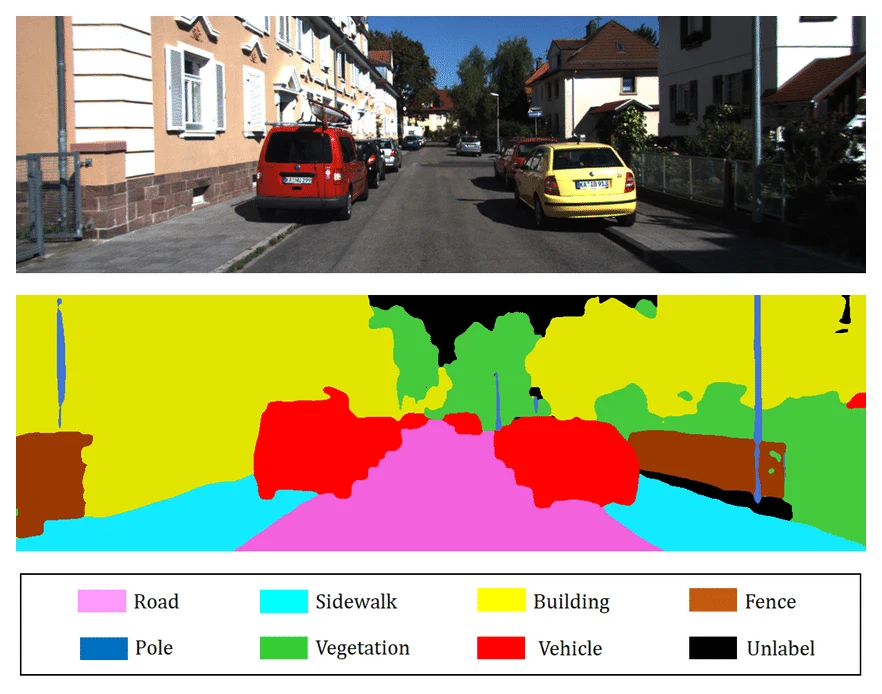
Semantic segmentation commonly uses mIoU (mean Intersection over Union): like detection, compute IoU per class (same as the figure above), then average.
Super-resolution, image restoration, image compression and the like commonly use PSNR (Peak Signal to Noise Ratio). Higher PSNR means smaller error between the processed and original image; typical values in image compression sit between 30dB and 50dB:
Efficiency-oriented performance
Efficiency splits into time and space. Since training happens once but inference runs over and over after deployment, the focus here is on inference efficiency (speeding up training itself is a separate topic).
Time: latency, FLOPs, and where FLOPs lie
Time efficiency is mainly inference latency — how long one forward pass takes. Latency depends on three things: the model itself, the software implementation, and the hardware platform. All three strongly affect any measurement, so when optimizing the model you have to measure in a stable software/hardware setup to rule out the rest: same docker image, same hardware, warm up the cache before measuring, average over several runs, and so on.
Since different researchers can rarely measure on one unified platform, a common workaround is the indirect metric FLOPs (floating point operations; some papers call it Mult-Adds) as a stand-in for latency. A CNN’s FLOPs concentrate in the convolution and fully-connected layers. For a conv layer:
where are the output feature map’s height/width, the input/output channels, the kernel size. For a fully-connected layer:
with the input/output dimensions. Tools for computing a network’s FLOPs already exist, e.g. the PyTorch-based torchprofile.
An indirect metric has limits: it can’t account for memory-access cost, nor for the speedups from parallelism and high-performance kernels. To see the gap, I measured FLOPs and same-platform GPU latency for a batch of classic networks, and broke down the FLOPs/latency share of convolution, matrix multiply (gemm), and everything else:
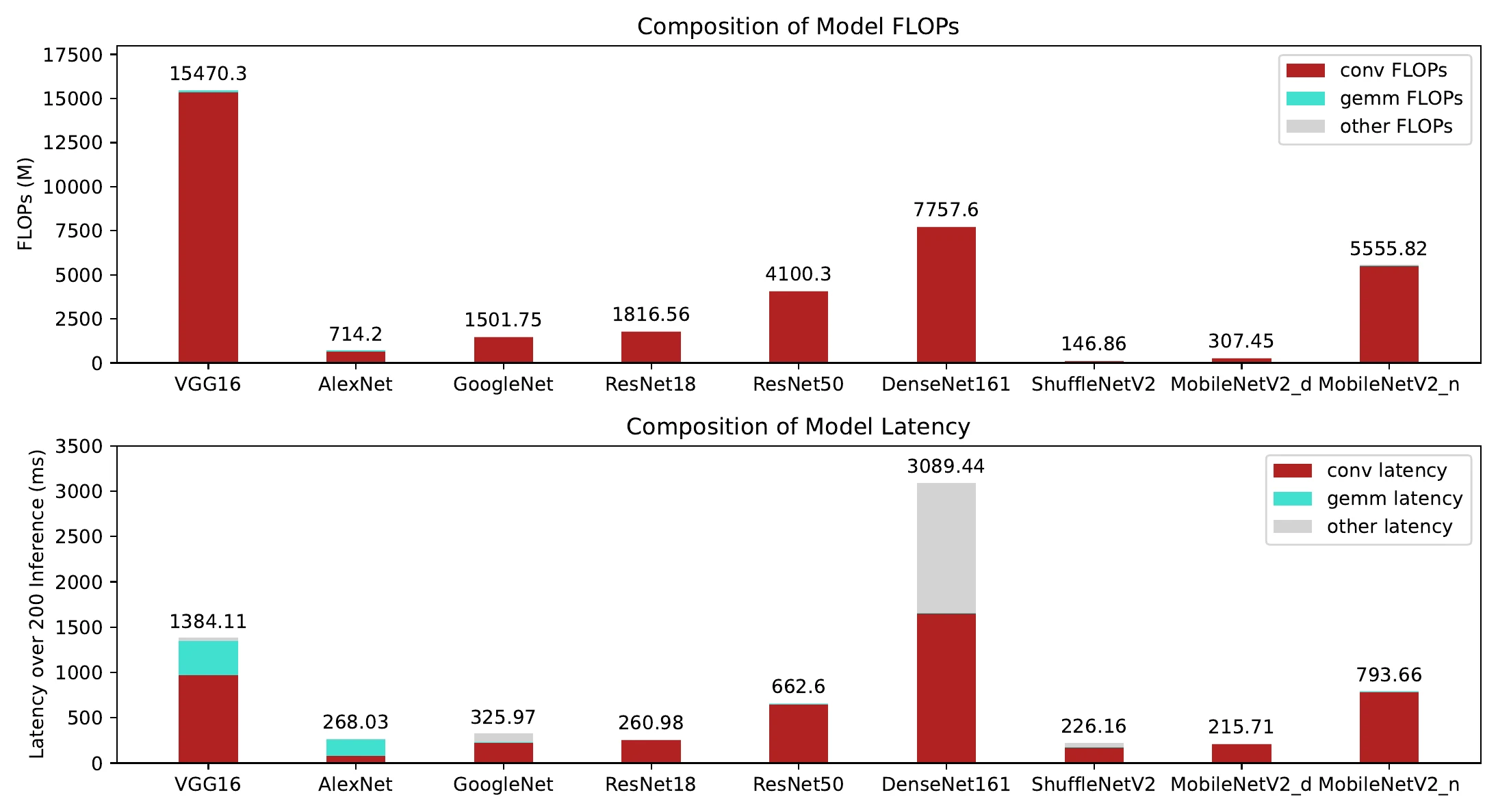
FLOPs and latency correlate overall, but a few exceptions jump out — the starkest being VGG16 and DenseNet161, reversed. VGG16 has 15470.3M FLOPs and 1384.11ms GPU latency (total of 200 consecutive inferences after warmup, converted to TensorRT); DenseNet161 has only 7757.6M FLOPs — half of VGG16’s — yet more than double the latency. The reason: FLOPs count only compute, not memory access. DenseNet161 has a huge number of Copy operations (about 10× the conv ops after converting to TensorRT), whose cost doesn’t show up in FLOPs at all. Even setting Copy aside, DenseNet161 is still slightly slower than VGG16: it has 160 conv operations versus VGG16’s 13 — VGG16 has higher FLOPs but far fewer conv ops, so less memory access, and it runs faster. ShuffleNetV2 is similar: its Split, Reshape, and Transpose take ~20% of the time but never appear in the FLOPs.
Another telling case: in AlexNet, gemm operations are only 8.2% of total FLOPs but 67.7% of the latency. (Unfortunately the experiments ran inside a docker container without access to the NVIDIA GPU Performance Counters, so I couldn’t dig into the kernels further.)
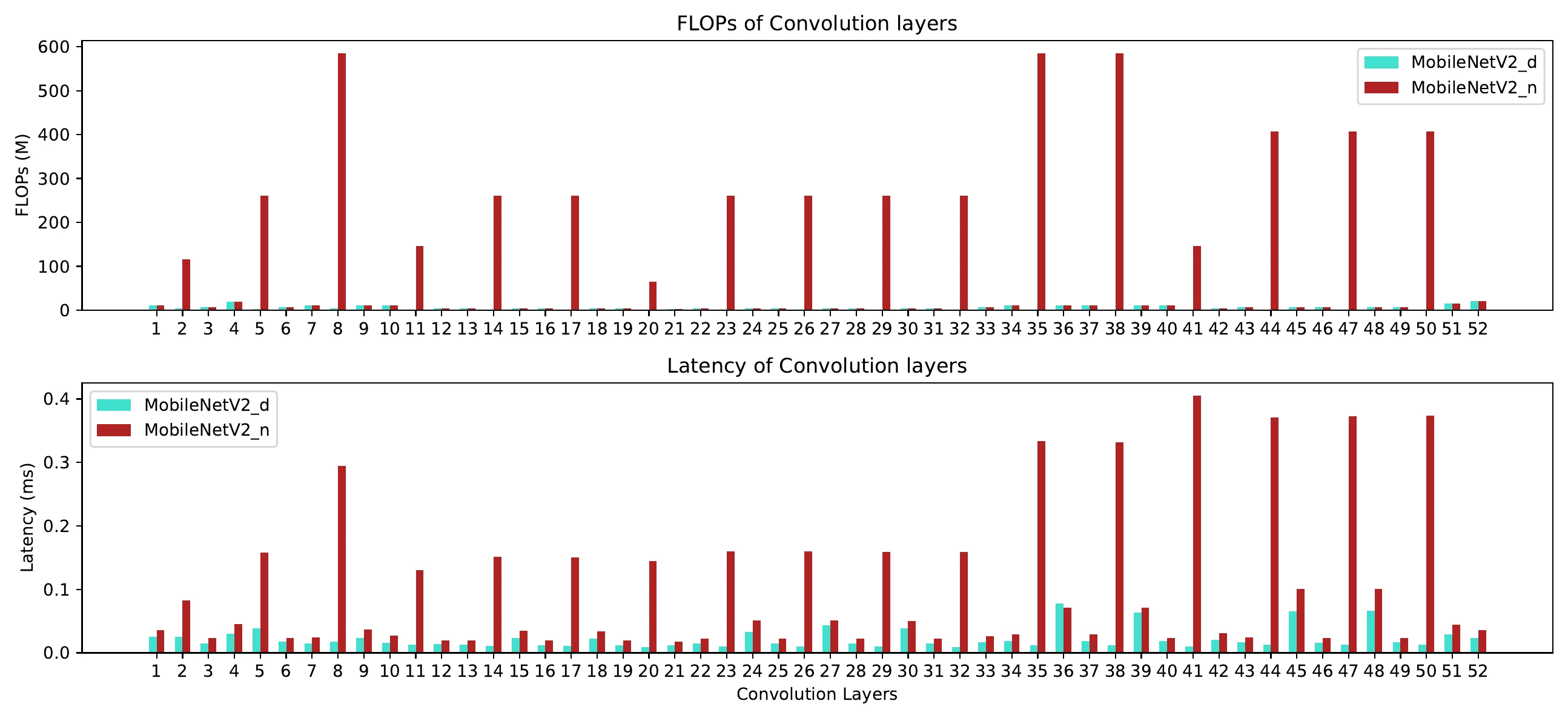
Finally, depthwise convolution. Below, MobileNetV2_d uses depthwise convolutions while MobileNetV2_n replaces all of them with normal convolutions. MobileNetV2_d has 18× fewer FLOPs than MobileNetV2_n, yet is less than 4× faster — a per-layer comparison shows depthwise convolution slashes FLOPs but does little for memory-access cost:
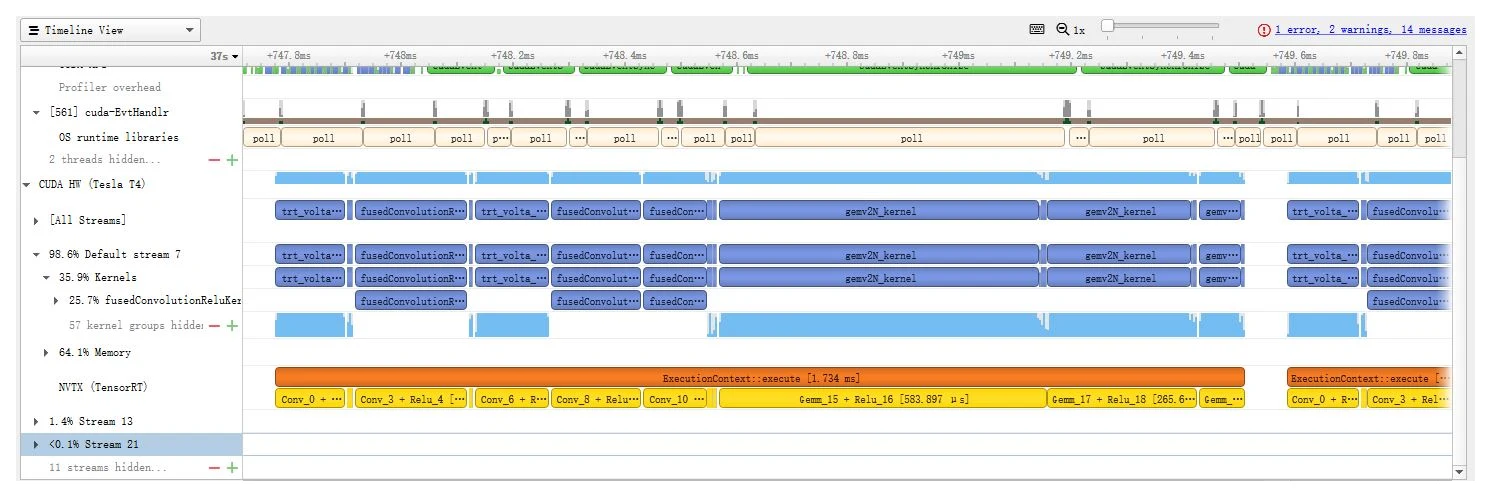
Since the time goes mostly into conv and FC layers, on a GPU you can use NVIDIA Nsight Systems or TensorRT’s built-in profiler to measure each part directly and optimize where it counts — because optimizing different parts helps the whole by different amounts. That’s Amdahl’s law:
where is the fraction of the original execution time the optimized part takes, and is that part’s own speedup.
Space: parameters and peak memory
Space efficiency is mainly the runtime memory footprint. It too depends on the network structure and the software implementation (some inference frameworks promptly free feature maps already consumed by the next layer, or use inplace depthwise convolution, or run in FP16). Here we assume all parameters are stored and computed in 32-bit float, and discuss only the structure itself.
Memory has two sources: the network’s own parameters (which occupy memory at runtime and disk when stored), and the runtime peak memory, which comes mostly from the live feature maps and depends not only on the structure but also on the input size (batch, height/width, channels). The literature discusses parameter count far more than peak memory, but for multi-branch structures, running a node with many input branches means holding many feature maps at once — peak memory can be large even when such a network has few parameters.
Like FLOPs, memory can be computed fairly accurately without depending on the runtime platform. Parameters again come mostly from conv and FC layers. Conv (with bias):
Fully-connected:
As for peak memory, if inference only stores the weights plus the feature maps it currently needs, then the runtime maximum is roughly all the weight parameters plus the largest single set of feature maps held during the run.
Once both lines — task accuracy and runtime efficiency — are defined, every later step (architecture design, training tricks, pruning, quantization) finally has a yardstick to line up against.
References
- He, Kaiming, et al. Deep Residual Learning for Image Recognition. CVPR, 2016.
- Howard, Andrew G., et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv:1704.04861, 2017.
- Sandler, Mark, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks. CVPR, 2018.
- Howard, Andrew, et al. Searching for MobileNetV3. arXiv:1905.02244, 2019.
- Paszke, Adam, et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. NeurIPS, 2019.
- Abadi, Martín, et al. TensorFlow: A System for Large-Scale Machine Learning. OSDI, 2016.