图像数据增强:从随机裁剪到自动增强
数据增强是计算机视觉任务里为了防止过拟合、在训练时经常使用的方法。这篇先介绍几种常用的图像增强,再介绍一些自动化的数据增强方法。
常用的图像数据增强
Random resized crop 把输入图片随机裁剪后缩放到给定尺寸,在 PyTorch 里是 torchvision.transforms.RandomResizedCrop(size, scale, ratio):size 是最终缩放到的尺寸;scale 是一个范围,表示随机裁剪区域占原图大小的比例范围;ratio 也是一个范围,表示裁剪区域的长宽比范围。
Cutout 随机把图片以一个正方形遮掉一部分(把像素值置 0):

Random erase 与 Cutout 类似,同样随机遮挡一部分,区别在于用的是长方形而非正方形:

Mixup 通过随机加权地混合两张输入及其标签,创造出一些”虚拟”的训练样本:
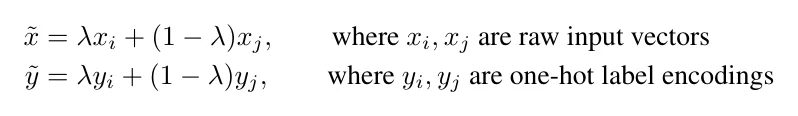
除此之外还有很多常见手段:随机翻转、随机旋转,调整对比度、亮度、锐度等等。
自动化数据增强
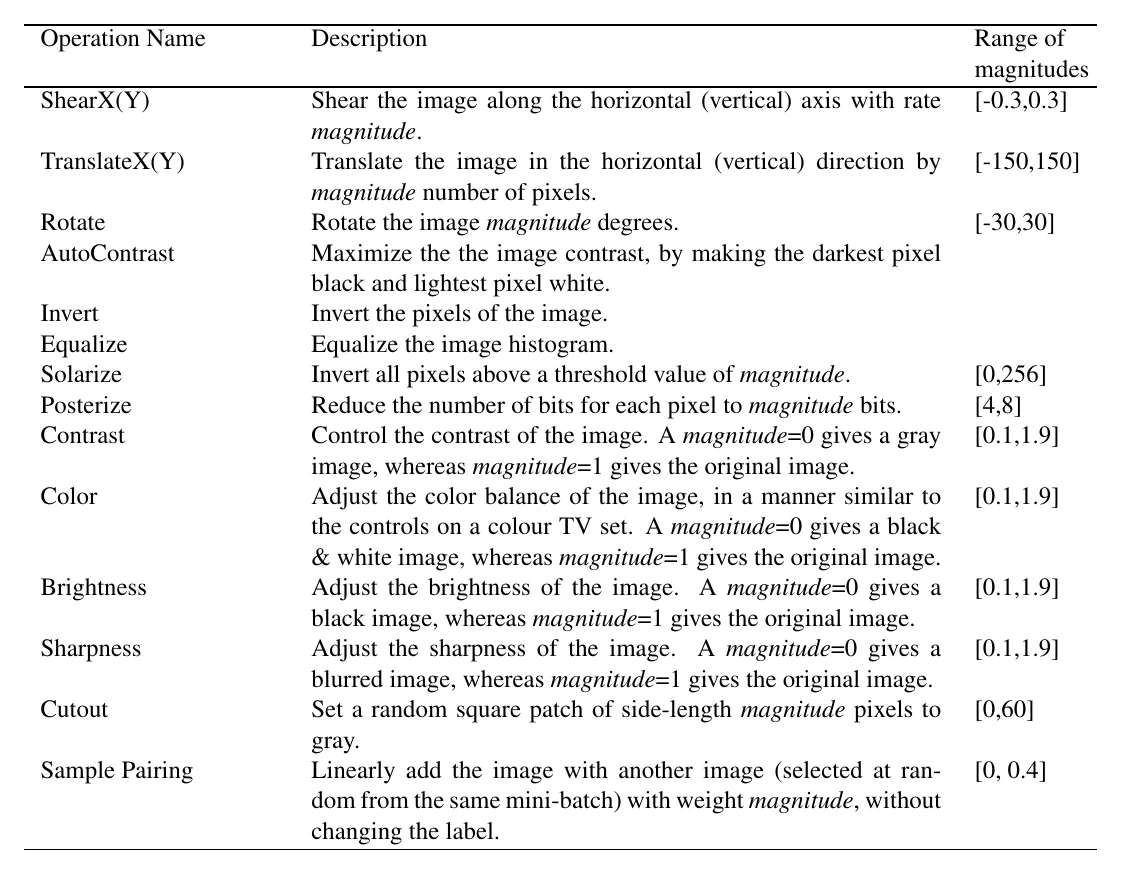
AutoAugment 把多种数据增强操作及其强度组织成一个搜索空间,再自动搜出效果最好的组合(每个组合含两个操作,每个操作有”概率”和”强度”两个参数)。
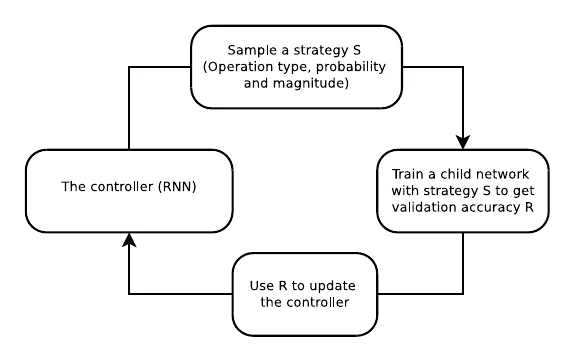
它的搜索方式很像 NAS——用 RNN 来采样策略、用强化学习来更新。每个候选策略都要训练一个网络来验证效果,因此非常耗时。
把这种组合式增强用到 ImageNet 上的结果如下:

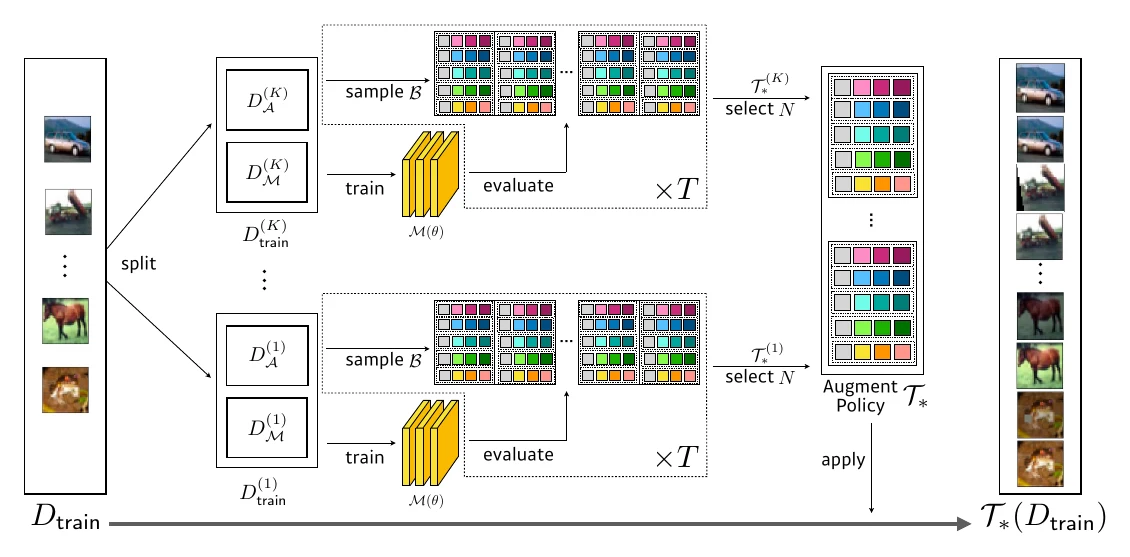
Fast AutoAugment 则快得多,曾赢得 AutoCV 竞赛冠军;我也用它拿过 AutoDL 竞赛图像赛道的冠军。它的提速主要在于:把数据集分成多个部分分别搜索最佳增强策略,最后再把这些策略合在一起。我在竞赛里还把原论文的贝叶斯优化换成了随机搜索,并用 AutoAugment 的搜索结果作为搜索空间。
最后补一句:除了训练时增强,还可以做测试时增强(Test Time Augmentation, TTA)——把测试样本做数据增强后分别推理,再把多个结果集成起来作为最终输出。
参考资料
- DeVries, Terrance, Taylor, Graham W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv:1708.04552, 2017.
- Zhong, Zhun, et al. Random Erasing Data Augmentation. AAAI, 2020.
- Zhang, Hongyi, et al. mixup: Beyond Empirical Risk Minimization. arXiv:1710.09412, 2017.
- Shorten, Connor, Khoshgoftaar, Taghi M. A Survey on Image Data Augmentation for Deep Learning. Journal of Big Data, 2019.
- Cubuk, Ekin D., et al. AutoAugment: Learning Augmentation Policies from Data. arXiv:1805.09501, 2018.
- Lim, Sungbin, et al. Fast AutoAugment. NeurIPS, 2019.
- Zoph, Barret, Le, Quoc V. Neural Architecture Search with Reinforcement Learning. arXiv:1611.01578, 2016.