深度学习调参:从手动炼丹到自动搜索
调参在深度学习的训练里既玄学又重要,以至于训练过程常被戏称为”炼丹”,不少算法工程师也自称”调参侠”。这篇先讲一些手动调参的技巧,再讲自动调参的方法与工具。
手动调参
以 ImageNet 分类为例,训练时要调的超参数大多和优化相关:batch size(下称 BS)、优化器选择,以及优化器相关的学习率(learning rate,下称 LR)、学习率衰减策略、动量、权重衰减系数等。
Batch size 与学习率
BS 的取舍有两个角度。从硬件看:BS 太大容易内存溢出(OOM),太小又不能充分利用算力、拖慢训练。从优化看:较大的 BS 能更好地估计整个数据集的梯度,优化更稳、不易发散,因此通常较大的 BS 会配较大的 LR 来加速训练。一个常用经验是等比例缩放 BS 和 LR:比如 BS=256 对应 LR=0.1,那么用 4 张 GPU、每张 BS=256(总 BS=1024)时,LR 就该放大到 0.4。另外 BS 通常设成 ,以提高并行效率。
优化器
神经网络的优化,本质是估计权重 、最小化目标函数 。 个样本时:
标准梯度下降按全体样本更新( 为学习率):
但深度学习里 很大,不可能每步都遍历全集,于是用一个 mini-batch(大小即 BS,记为 )来估计梯度,这就是带 mini-batch 的随机梯度下降(SGD):
下文用 指代这个 mini-batch 平均梯度。实际中常引入动量(momentum),按比例 把上一步的更新量带到这一步:
Nesterov 动量与之类似,区别是先按动量走一步、再在那个位置算梯度(PyTorch 里默认 ,即不用动量,我自己常设 ):
SGD 的学习率始终恒定。下面几种则能自适应学习率。Adagrad 用累积的梯度平方和来缩放学习率,除 外没有额外超参:
RMSprop 用一个衰减因子 淡化历史累积(PyTorch 默认 ):
Adam 相当于在 RMSprop 基础上又引入了梯度的动量,除 外还有 两个超参(PyTorch 默认 ):
学习率衰减与权重衰减
所有优化器都至少要调一个学习率 。LR 大概是训练里最重要的超参数,它和 BS、优化器、数据、模型都相关,没有标准答案,通常的准则是在不发散的前提下用尽可能大的学习率。LR 一般先 warmup(慢慢增大)再衰减,衰减策略有阶跃(step)、指数(exponential)、cosine 等:
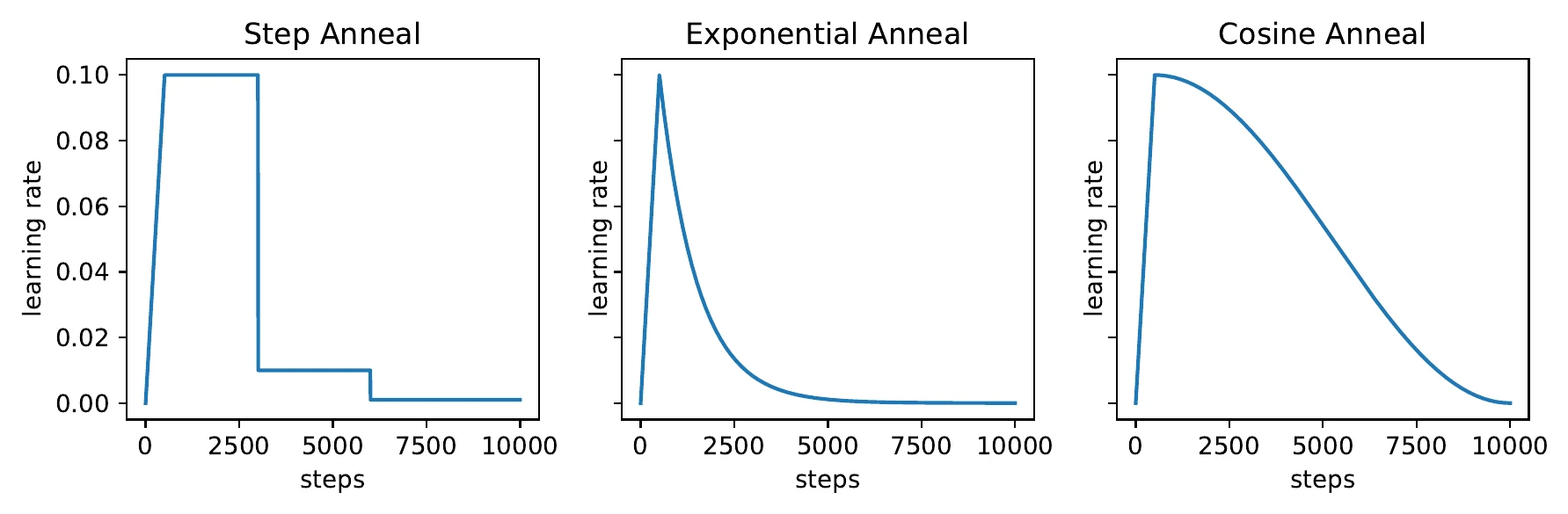
除了预设策略,也可以用自动学习率控制:盯住某个训练指标(如训练损失),预设一些规则——比如损失长时间不降就按比例衰减 LR、损失突然增大就衰减、损失下降很慢就适当放大。这类规则化方法在自动化深度学习里很有用,缺点是规则本身要花不少时间设计、还要尽量覆盖各种任务。我在 NeurIPS 2019 AutoDL 竞赛图像赛道的冠军方案里就用了这种方法。
最后是权重衰减(weight decay):在目标函数里加一个惩罚项(通常是 L1/L2,PyTorch 默认 L2)来防过拟合。系数一般不大,我常用 。一个小技巧是别对 BN 层的参数加权重衰减——BN 参数比卷积/全连接更敏感,加了之后精度反而会略降。
自动超参数优化
自动超参数优化属于 AutoML 的范畴(AutoML 还包括元学习、神经网络结构搜索 NAS 等)。这里只谈用黑盒优化做超参数优化(HPO)。黑盒方法大致分两类:无需模型的方法和贝叶斯优化。
无需模型的方法
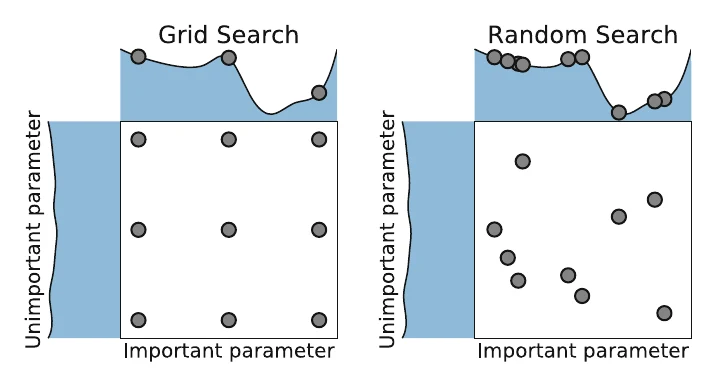
最简单的是网格搜索(Grid Search):为每个超参数设一个候选取值集合,做笛卡尔积后逐一验证。问题是随着超参数增多,计算量指数爆炸,即”维度灾难”。
替代品是随机搜索(Random Search):在解空间里随机采样,直到耗尽给定预算。当某些超参数重要、另一些不重要时,随机搜索往往比网格搜索更高效;它也更易并行(搜索时无需通信),还能作为不错的 baseline——给足算力时结果会无限逼近最优,且可以拿来当其他算法的初始值。
此外还有基于群体的算法(遗传/进化/粒子群):维护一个超参数群体,靠选择、交叉、变异等局部操作迭代出更优的下一代,简单、能处理各种数据类型、也好并行。其中性能很强的是 CMA-ES(自适应协方差矩阵进化策略):从一个多元高斯里采样,而该分布的均值和协方差随进化不断被优化,在黑盒优化基准(BBOB)上成绩很好。
贝叶斯优化
贝叶斯优化最大的优点是用很少的步数就能找到不错的超参组合,特别适合目标函数本身计算量大的场景(比如深度学习)。它分两部分:概率代理模型(surrogate model) 对黑盒目标建模,采集函数(acquisition function) 决定下一个观测点——后者要在探索与利用之间权衡。整个过程是迭代的:每轮先用代理模型拟合已有观测,再用采集函数挑下一个点。
代理模型最常用高斯过程(GP):表达力强、平滑、计算封闭。对一个新点 ,GP 预测的输出服从高斯分布,其均值与方差为(其中 是新点与历史点的协方差向量, 是历史点之间的协方差矩阵, 是历史观测值):
采集函数常用期望增益(Expected Improvement, EI),目标是找期望增益最大的点作为下一轮观测:
其中 是当前最优观测值, 是标准正态的 CDF 和 PDF。由于每轮都要找采集函数最大的点,采集函数的计算必须远快于目标函数——目标函数是大计算量的深度学习任务时,贝叶斯优化就很合适。
标准 GP 也有短板:计算复杂度高(拟合 、预测 ),观测点一多就吃不消;标准核函数在高维下也不够灵活。于是有了各种扩展核(随机嵌入、圆柱核、加法核),以及用神经网络或随机森林替代 GP——观测点多时神经网络通常更快也更好并行,随机森林则更擅长处理离散超参、复杂度也更低(拟合 、预测 )。
工具
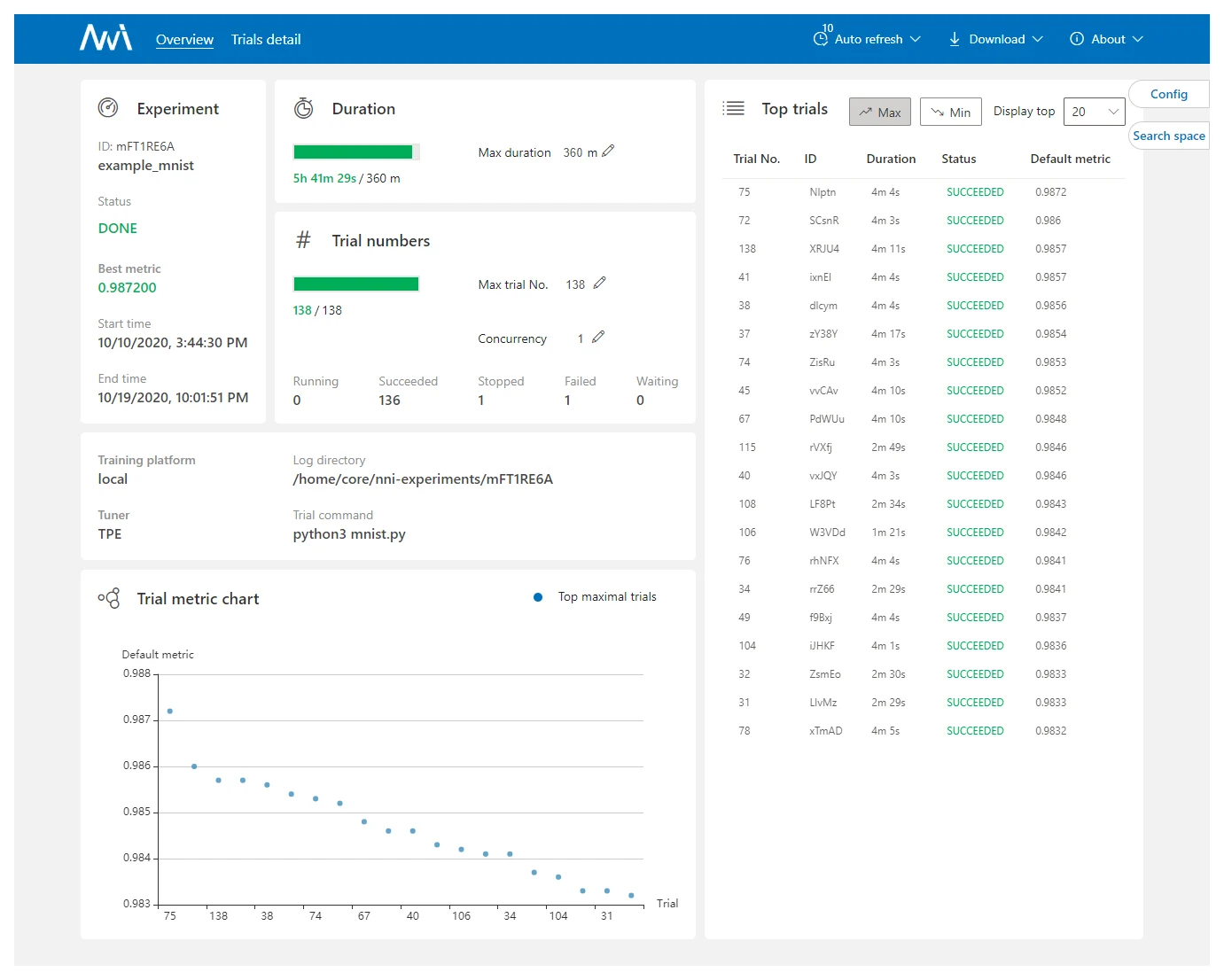
不少工具已经集成了上述算法,还带有可视化界面和跨平台支持,例如 RAY、NNI、Auto-sklearn 等。其中 NNI(Neural Network Intelligence)是个轻量但强大的工具包,能自动做特征工程、结构搜索、超参调优和模型压缩,支持本机、远程服务器、Kubeflow、AML 等多种训练环境,界面上可以直观地监控整个优化过程的时间开销与效果:
参考资料
- Deng, Jia, et al. ImageNet: A Large-Scale Hierarchical Image Database. CVPR, 2009.
- He, Tong, et al. Bag of Tricks for Image Classification with Convolutional Neural Networks. CVPR, 2019.
- Duchi, John, et al. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization (Adagrad). JMLR, 2011.
- Kingma, Diederik P., Ba, Jimmy. Adam: A Method for Stochastic Optimization. arXiv:1412.6980, 2014.
- Sutskever, Ilya, et al. On the Importance of Initialization and Momentum in Deep Learning. ICML, 2013.
- Bergstra, James, Bengio, Yoshua. Random Search for Hyper-Parameter Optimization. JMLR, 2012.
- Hansen, Nikolaus. The CMA Evolution Strategy: A Comparing Review. 2006.
- Rasmussen, Carl Edward. Gaussian Processes in Machine Learning. 2003.
- Jones, Donald R., et al. Efficient Global Optimization of Expensive Black-Box Functions. Journal of Global Optimization, 1998.
- Li, Lisha, et al. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. JMLR, 2017.
- Falkner, Stefan, et al. BOHB: Robust and Efficient Hyperparameter Optimization at Scale. arXiv:1807.01774, 2018.
- Zhang, Quanlu, et al. Retiarii: A Deep Learning Exploratory-Training Framework (NNI). OSDI, 2020.