ShuffleNet: An Ultra-Efficient Convolutional Neural Network for Mobile Devices
Abstract
This article introduces a highly efficient network, ShuffleNet, which primarily utilizes pointwise group convolution and channel shuffle operations. These techniques significantly reduce computational costs while maintaining accuracy, outperforming previous networks on ImageNet and COCO.
1. Introduction
Building deeper and wider neural networks is a trend in solving visual recognition problems. However, this article proposes another extreme: achieving optimal performance with limited computational resources. Many existing methods (such as pruning and compression) only deal with basic neural networks, whereas this article presents an efficient network structure given specific computational resources.
Current state-of-the-art networks are resource-intensive, mainly due to dense 1x1 convolutions. This article uses 1x1 group convolution to reduce computation and channel shuffle to enhance communication between channels, encoding more information. Based on these two techniques, ShuffleNet is constructed, achieving better performance on ImageNet and COCO, with noticeable acceleration on real hardware platforms.
2. Related Work
Efficient Model Designs: GoogLeNet increased network depth while reducing computation compared to simple convolutional layer stacking. SqueezeNet significantly reduced computation while maintaining accuracy. ResNet achieved high performance using an efficient bottleneck structure. SENet introduced a structural unit to accelerate performance with minimal computation. Recently, reinforcement learning and model search have been used to explore efficient model designs, with NASNet achieving good accuracy but performing averagely under smaller FLOPs.
Group Convolution: Group convolution was first introduced in AlexNet for distributed training on multiple GPUs and later demonstrated effectiveness in ResNeXt. Xception’s depthwise separable convolution summarized ideas from the Inception series, and MobileNet achieved state-of-the-art results using depthwise separable convolution.
Channel Shuffle Operations: The concept of channel shuffle has rarely been proposed in previous work. Although cuda-convnet supports “random sparse conv” layers, equivalent to random channel shuffle with a subsequent group convolution layer, recent work applied this idea in two-stage convolution without demonstrating the effectiveness of channel shuffle in small model design.
Model Acceleration: This aims to accelerate inference while preserving model accuracy. Pruning network connections or channels can remove redundant connections while maintaining performance. Quantization and factorization reduce computational redundancy, accelerating inference. Optimized convolution algorithms like FFT reduce actual time consumption without modifying parameters. Distilling can train smaller models from larger ones, making training smaller models easier.
3. Approach
3.1 Channel Shuffle for Group Convolutions
Many current state-of-the-art networks, such as Xception and ResNeXt, have too many 1x1 convolutions, consuming significant computation in each block. With limited computational resources, fewer channels are possible, reducing model accuracy. Sparse connections between channels, like group convolution, can solve this problem. However, this weakens connections between channel groups. Channel shuffle allows group convolution to gather information from different groups, solving this issue. The operation involves transposing, flattening, and reshaping dimensions (g,n), where g is the number of groups and n is the number of channels per group. This shuffle operation is effective even with different group numbers in two convolutions and is differentiable. 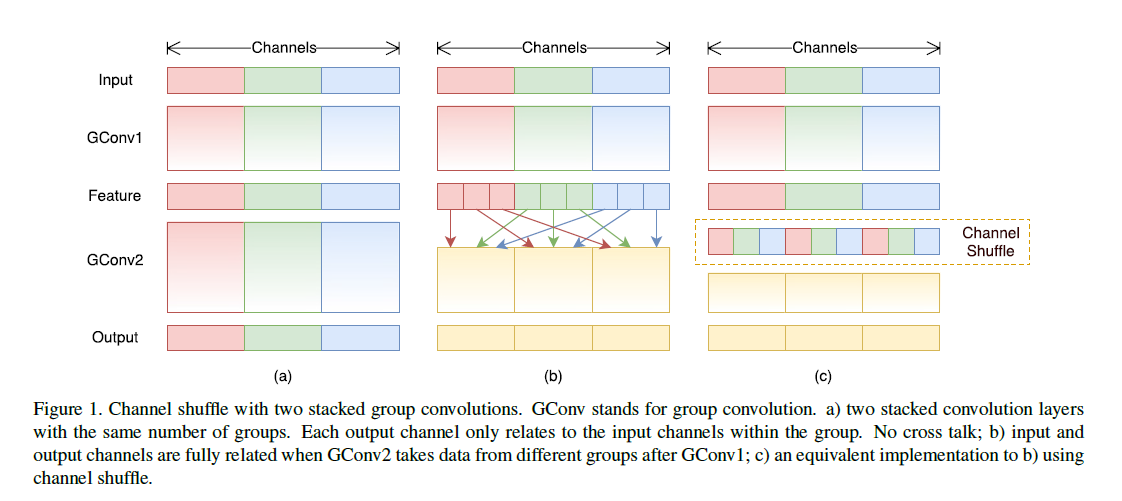
3.2 ShuffleNet Unit
This unit is designed for small networks, using a bottleneck structure. There are two types: one without stride, where input and output dimensions are the same, using a residual structure with summation, and another with stride, also using a residual structure but with concatenation. Compared to ResNet and ResNeXt, this unit is more efficient. For given input dimensions and bottleneck channel number , ResNet’s FLOPs are , ResNeXt’s FLOPs are , and ShuffleNet unit’s FLOPs are , allowing wider feature maps with given computational resources. Although depthwise convolution has low theoretical complexity, its FLOPs/MAC is small, mentioned later in ShuffleNetV2, so depthwise conv is only used in the bottleneck. 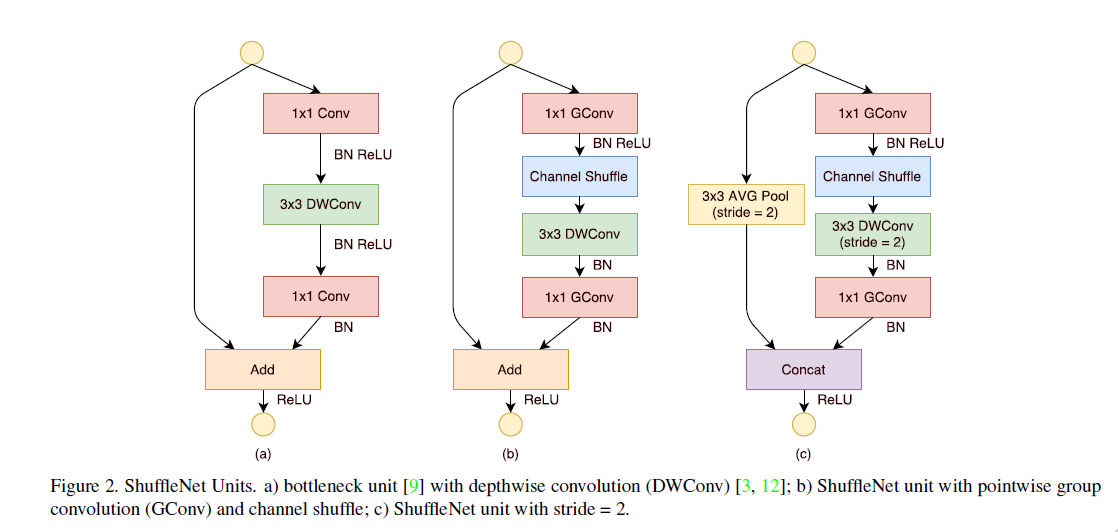
3.3 Network Architecture
In the entire network, for simplicity, the bottleneck channel number is of the input. A simple reference model is provided, although further tuning may yield better results. Parameter controls connection sparsity; more groups may help encode more information, but may reduce performance for a single convolution. ShuffleNetV2 discusses this from another angle: too many groups increase MAC, reducing speed. A hyperparameter scales the network, adjusting channel numbers. 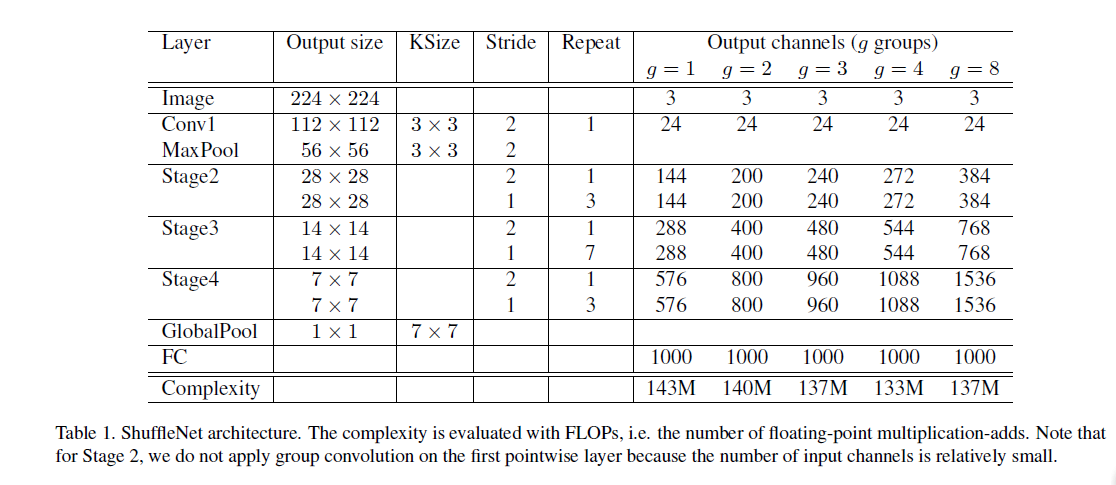
4. Experiments
Experiments were mainly conducted on ImageNet, using minimal data augmentation due to the risk of overfitting in small networks.
4.1.1 Ablation Study
Two main components of ShuffleNet are analyzed: pointwise group conv and channel shuffle.
For pointwise group conv, networks with different scales (scaling s) and groups were compared. Experiments show that for larger networks, when the group reaches a certain value, the input channel number for a single conv becomes too small, affecting performance. However, for smaller networks, increasing the group size significantly improves performance, as wider feature maps benefit small networks more. 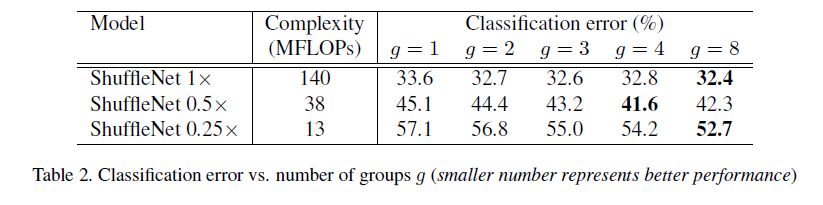
For channel shuffle, experiments show it significantly improves classification scores, especially with larger groups, where cross-group information exchange is crucial. 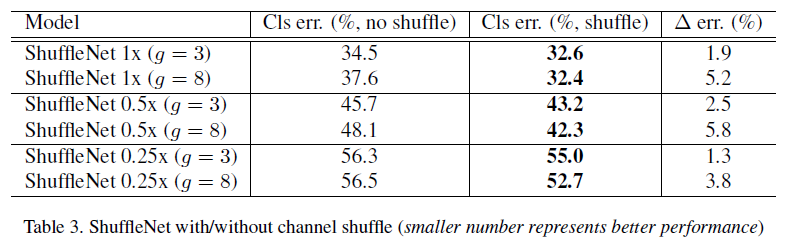
4.2 Comparison with Other Structure Units
ShuffleNet was compared with other units within the ShuffleNet framework, with results shown in the figure. 
4.3 Comparison with MobileNets and Other Frameworks
ShuffleNet was compared with other classic structures. Notably, reducing ShuffleNet’s depth still outperforms MobileNet, indicating that ShuffleNet’s key advantage lies in unit design rather than network depth. Combining ShuffleNet with other excellent designs like the SE module (Squeeze-and-Excitation) can further enhance performance but may slow it down. 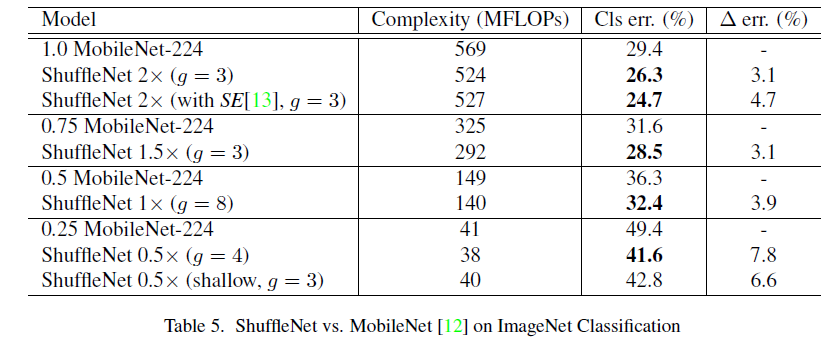
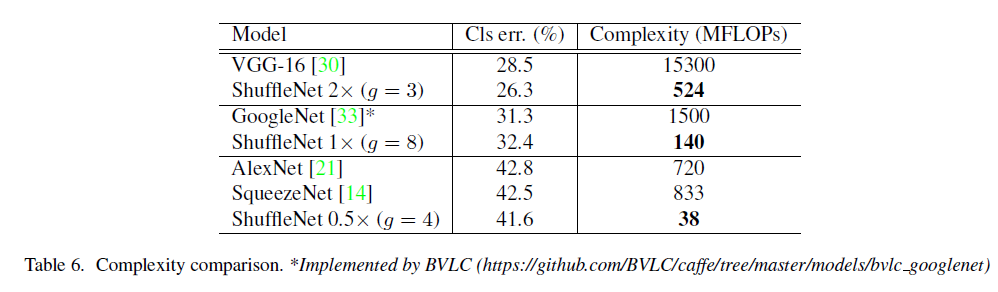
4.4 Generalization Ability
To explore ShuffleNet’s generalization and transfer learning performance, tests were conducted on COCO using the Faster-RCNN framework. ShuffleNet outperformed MobileNet significantly, possibly due to its network structure design without excessive redundant decorations, resulting in better generalization. 
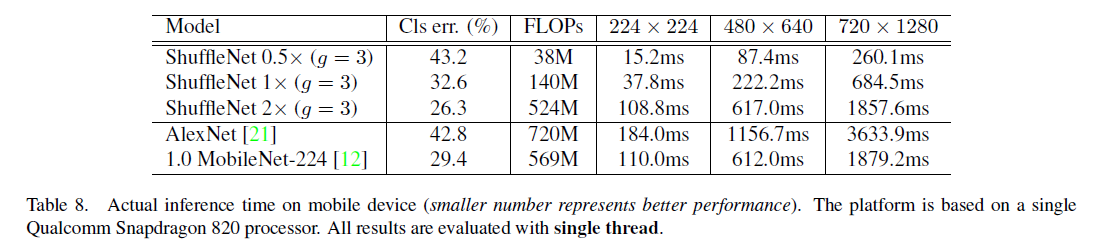
4.5 Actual Speedup Evaluation
Tests were conducted on the ARM platform. Performance was best with a larger group number (e.g., g=8), but g=3 offered a good balance between performance and inference time, still outperforming other networks.