ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Abstract
本文介绍了一种很高效的网络ShuffleNet,其主要在于pointwise group conv和channel shuffle两种操作,可以在维持精度的时候大量减少计算消耗,在ImageNet和COCO上面的表现都超过了之前的网络
1.Introduction
构造更深,更宽的神经网络在解决视觉识别上面是发展趋势。然而本文提出另外一个极端:在有限的计算资源下达到最佳的性能。现有的很多方法(剪枝压缩等)都只是在处理基本的神经网络,而这里提出了一种给定计算资源下的高效网络结构。
现在的state-of-the-art网络对资源都比较消耗计算资源,主要是因为太密集的1x1 conv,本文使用了1x1 group conv来减小计算量,并且使用channel shuffle来增加各个channel之间的通讯,这样可以编码更多信息,基于这两个技术而构建了ShuffleNet,基于这两个设计准则,在ImageNet和COCO上都取得了更好的性能,另外在真实的硬件平台上也有明显的加速效果
2.Related Work
Efficient Model Designs:GoogLeNet增加了网络深度但是相比简单的conv层堆积减少了计算量。SqueezeNet在维持精度的情况下明显减少了计算量。ResNet利用有效的瓶颈结构来得到较高的性能。SENet引入了一个结构单元在小计算量的情况下加速性能。另外最近有工作利用强化学习和模型搜索来探索高效的模型设计,得到的NASNet得到了不错的精度表现,但是在较小的FLOPs下表现比较一般。
Group Convolution:group conv最开始在AlexNet当中被提出,当时是为了在多个GPU上进行分布式训练,后来在ResNeXt当中表现了其有效性。Xception中的Depthwise separable conv总结了Inception系列网络的想法,后来MobieNet利用depthwise separable conv实现了state-of-the-art。
Channel Shuffle Operations:channel shuffle的思想在之前的工作中很少被提出来,即使cuda-convnet支持”random sparse conv”层,等价于后面带有group conv层的random channel shuffle。最近有工作在two-stage conv上应用这个思想但是却没有channel shuffle自身在小模型设计上的有效性。
Model Acceleration:这个是为了在保留模型精度的时候加速推断,对网络连接或者通道进行剪枝可以在保留性能的时候去掉冗余的连接。quantization和factorization可以减少计算当中的冗余从而加速推断。另外在不修改参数的时候,优化的卷积算法比如FFT都会减少实际当中的时间消耗。另外distilling可以从大模型中训练小模型,可以让训练小模型变得更加容易。
3.Approch
3.1 Channel Shuffle for Group Convolutions
现在的很多state-of-the-art网络,比如Xception和ResNeXt都有太多的1x1 conv,在每个block中占了大量的计算量,如果在限制计算资源的情况下就只能有更少的channel数,这样会降低模型的精度。要解决这个问题可以使用channel之间的稀疏连接,例如group conv就是其中的一个例子。然而这样会导致一个组内的输出只与这个组内的输入相关,会导致channel group之间的联系变得较弱,可以通过channel shuffle可以让group conv从不同的group获取信息,从而解决这个问题。具体操作为(g,n)维度先转置,然后展开,然后再reshape为(g,n),其中g为group数,n为每组channel数。当两个卷积有不同的group数的时候依然是有效的,并且这个shuffle操作也是可以微分的。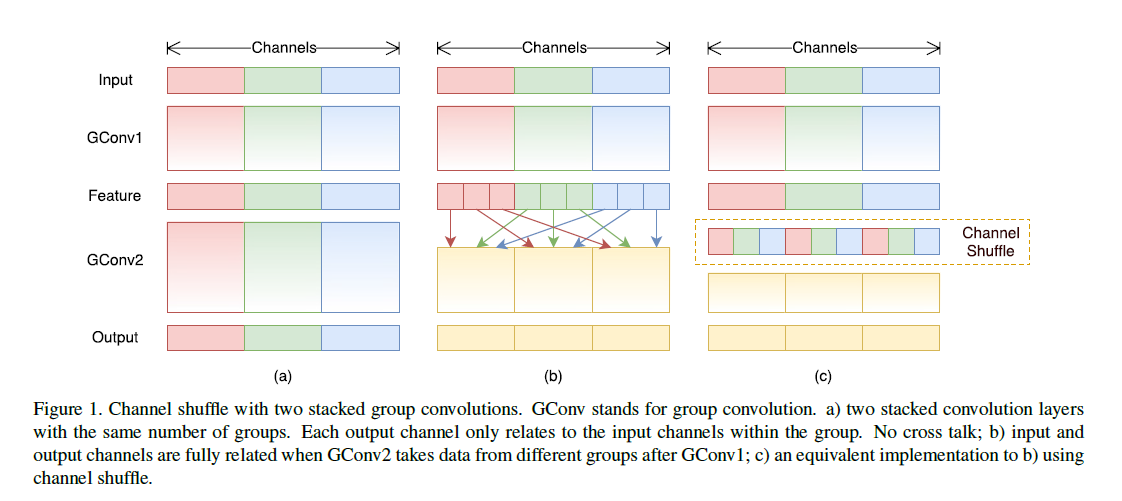
3.2 ShuffleNet Unit
这个unit是专门为小网络设计的,使用了bottleneck的结构。unit分为两种,一种是没有stride,输入输出维度一样的,采用残差结构,最后是求和。另外一种是有stride的,同样残差结构不过最后采用了concat。这个Unit相比ResNet和ResNeXt更加高效,比如给定输入维度,瓶颈通道数为,ResNet的FLOPs为,ResNeXt的FLOPs为,ShuffleNet unit的FLOPs为,也就相当于在给定计算资源的情况下ShuffleNet unit能够使用更宽的特征图。另外depthwise conv虽然只有很小的理论上的复杂度,但是FLOPs/MAC比较小,这个在后面的ShuffleNetV2中有提到,所以只在bottleneck那里使用depthwise conv。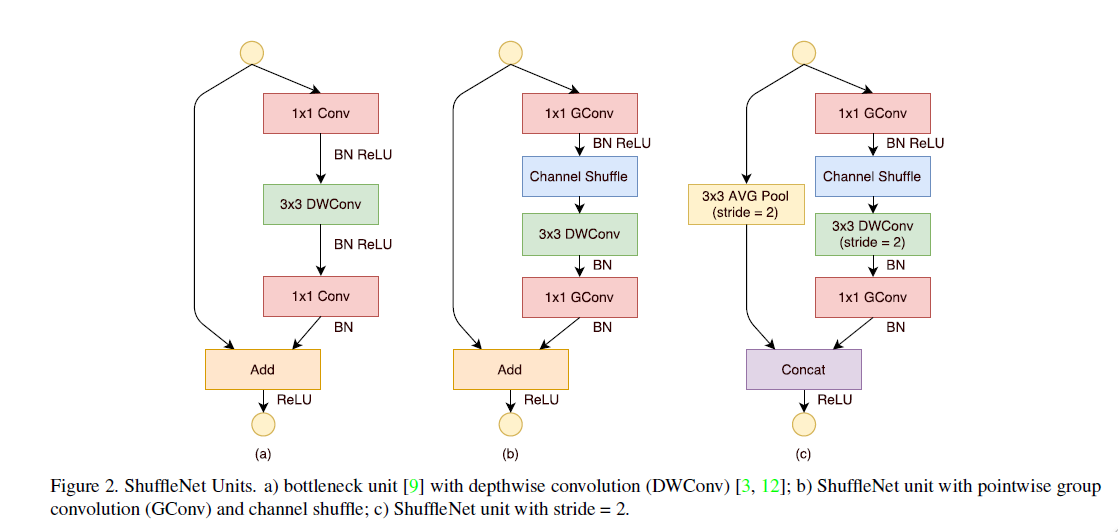
3.3 Network Architecture
在整个网络里面,为了简化,Bottleneck的channel数为输入的,这里提供一个尽可能简单的参考模型,尽管进一步调参可能会取得更好的结果。其中的参数控制连接的稀疏度,更多的group可能会帮助编码更多信息,但是对于单个conv可能会降低其性能,在ShuffleNetV2中也从另一个角度讨论了该问题:过多的group会增加MAC从而降低速度。另外用一个超参数来对网络进行缩放,通过缩放调整通道数来实现。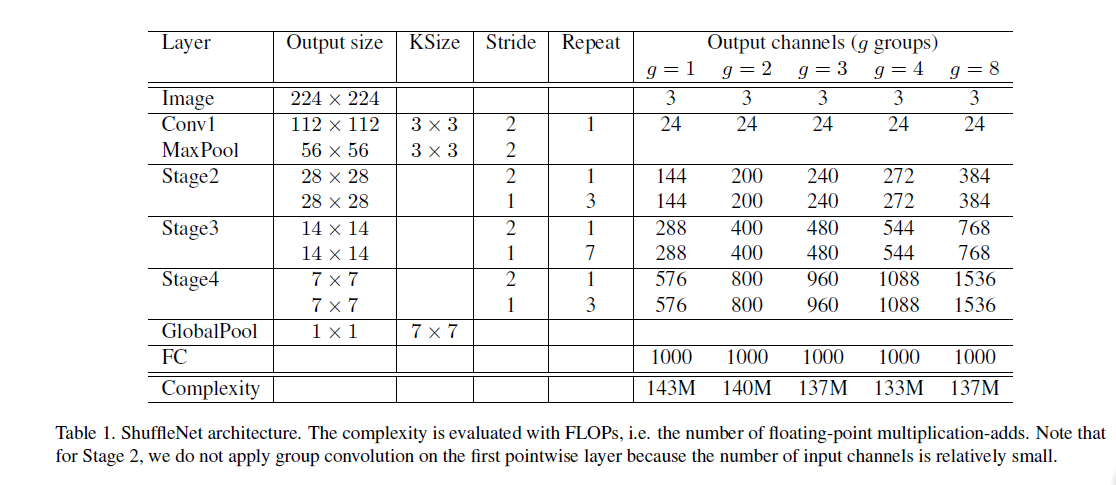
4.Experiments
主要在ImageNet上做的实验,因为小型网络更加容易遭遇过拟合,所以使用了很轻微的data augmentation。
4.1.1 Ablation Study
这里主要对于两个方面进行分析,一是pointwise group conv,二是channel shuffle。这两个是ShuffleNet的核心组件
对于pointwise group conv,这里利用不同规模(缩放s),不同group的网络进行对比,实验表明对于比较大的网络,当group达到一定值之后对于单个conv,其输入的通道数过少,将会影响表达性能。但是当缩放因子比较小的时候,网络比较小在group增大的时候更能明显提高性能,因为对于小网络而言,更宽的特征图可以带来更大的好处。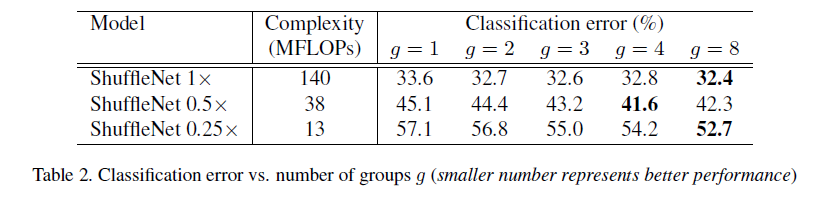
对于channel shuffle,实验证明channel shuffle明显能够持续提高分类分数,尤其当group比较大的时候性能更好,此时的跨组信息交换变得更加重要。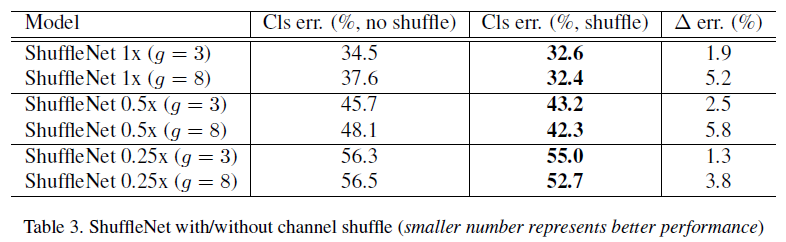
4.2 Comparison with Other Structure Units
在之前的ShuffleNet框架上与一些unit进行了对比,实验结果如图
4.3 Comparison with MobileNets and Other Frameworks
这里主要将ShuffleNet与其它一些经典的结构相比较,其中值得注意的是在ShuffleNet和MobileNet相比较的过程中,减少ShuffleNet的深度也明显会比MobileNet更好,这说明ShuffleNet与之相比关键在于unit的设计而非网络深度,另外可以将ShuffleNet与其他优秀设计比如SE模块(Squeeze-and-Excitation)相组合,可以进一步提升其性能但是会变得比较慢。

4.4 Generalization Ability
为了探究ShuffleNet的泛化和迁移学习的性能,在COCO上进行了测试,利用Faster-RCNN的框架来进行实验。在这项任务上依旧比MobileNet好了很多,可能是由于网络结构设计没有过多的冗余装饰,所以泛化性能比较好。
4.5 Actual Speedup Evaluation
这里在ARM平台上进行了测试,group数较大的时候(比如g=8)性能最好但是g=3的时候在性能和推断时间上有着比较好的平衡,但是依旧要比其他网络更优秀。