Data Suppliers Behind Large Models - Surge AI
Data Suppliers Behind Large Models - Surge AI
The first time I heard about Surge AI was through a podcast interview with Edwin Chen, coinciding with their first fundraising effort. Edwin’s insights were quite impressive:
- He dislikes the Silicon Valley hype game, preferring to do the right thing rather than something that just looks impressive.
- He opposes the approach of piling manpower to label data, focusing instead on producing the highest quality data and improving efficiency through optimized processes.
- He points out that public benchmarks (such as those based on user preferences like LMArena) do not work.
I strongly agree with their views. On one hand, I also dislike formulaic entrepreneurial paths, and on the other, I have experience in AutoML, having trained many models intensively to improve performance, which made me deeply understand the importance of data comprehension for model effectiveness. Out of interest in this company, this article organizes Surge AI’s company development, team, business situation, and their core viewpoints.
Surge AI Company Development and Team
Surge AI was founded in 2020 (after the release of GPT-3). Unlike most Silicon Valley companies, founder Edwin did not take VC investment but used his savings from working at major companies to start the company, achieving profitability from the start. In interviews, Edwin expressed his dislike for the Silicon Valley status game, such as fundraising, hype, tweeting, and networking, preferring to do the right things himself and not wanting to be constrained by VC money.
Surge AI initially provided high-quality data annotation (different from cheap large-scale crowdsourcing) and later added RLHF data and workflows, quality control, complex rubric design, domain expert annotation, rapid experimentation interfaces, red team tools, and other professional services. These services were deeply involved in Claude’s training.
The company’s revenue exceeded 1 billion fundraising in July 2025, with a valuation of around $30 billion.
CEO Edwin graduated from MIT and has worked in data science/machine learning roles at Twitter (search/ads quality), Google, and Facebook/Meta, gaining a deep understanding of data. The company has a very lean team, with less than 100 core members focusing on developing toolchains, platforms, and evaluation systems. Including part-time staff and consultants, there are about 250 people. Additionally, Surge AI collaborates with other contractors to complete labor-intensive tasks.
Business and Case Studies
Surge AI has limited public information, but some case studies can be found on their blog:
GSM8K Dataset Built for OpenAI (2022)
This is a dataset containing 8,500 elementary school math problems, all application problems, such as:
After Bobby gets paid, Darren will have twice as much money as Bobby. Bobby currently has 16 in wages. How much money does Darren have now?
The construction of this dataset required consideration of diversity and accuracy. See link for details.
Claude’s Training and Evaluation (2023)
In Claude’s model training and evaluation, Surge AI features were used:
- Quality control
- Domain expert annotation
- Rapid experimentation interface
- Red team tools
However, there is no detailed introduction. Original blog
AdvancedIF for Meta Superintelligence (2025)
Current public benchmarks are actually disconnected from real-world scenarios. Everyone focuses on easily evaluated metrics (like character count) rather than truly useful metrics. When building this evaluation system, Surge AI followed these principles:
- Construct genuine evaluation goals, not simple proxy goals (e.g., character count is easy to measure, but evaluating true writing ability is difficult).
- Use query data written by human experts rather than synthetic data.
- Evaluations need to be flexible, not treated as simple multiple-choice questions.
- Include complex multi-turn dialogues as features, as user interactions in each turn can be chaotic.
See original text for details.
In addition to the above client cases, Surge AI’s blog contains many interesting analyses, such as model evaluations on financial issues and programming issues. When tasked with creating a PPT on financial risk and making financial forecasts, GPT-5, Claude, and Gemini each have issues like hallucinations, formatting errors, and formula damage. In the SWE-Bench Bash Only test, Gemini 2.5 Pro, Claude Sonnet 4, and GPT-5 all experience hallucinations, but their hallucination trajectories are completely different.
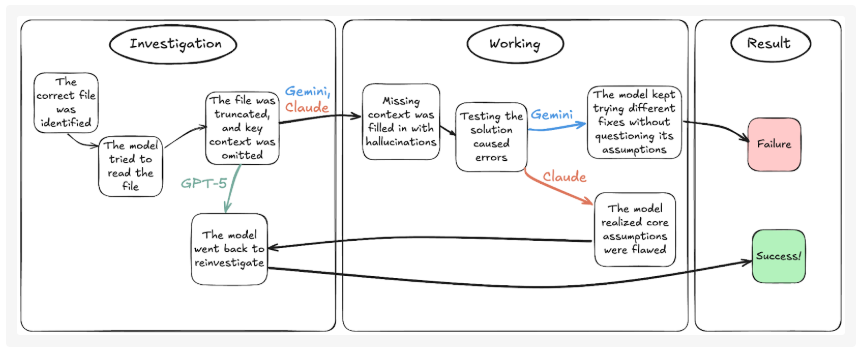
There’s also a simple case where both ChatGPT and Gemini failed at simple PDF text extraction.
Core Viewpoints
Public Benchmarks Have Many Issues
For example, LMArena: input a question, evaluate two answers, and select the best one.
This essentially optimizes for human attention rather than basic facts, as ordinary people do not fact-check; they vote for whichever is longer or has cooler emojis (ChatGPT also has this mechanism). This is actually unreasonable, but it is popular in the community and revered, with clients and investors referencing this leaderboard’s performance, forcing developers to optimize for an unreasonable evaluation system.
Moreover, many other benchmarks have a host of issues, such as 30% of answers in “Humanity’s Last Exam” being wrong, and 36% of answers in HellaSwag being incorrect. If the evaluation metrics themselves are flawed, the trained models will not be good either.
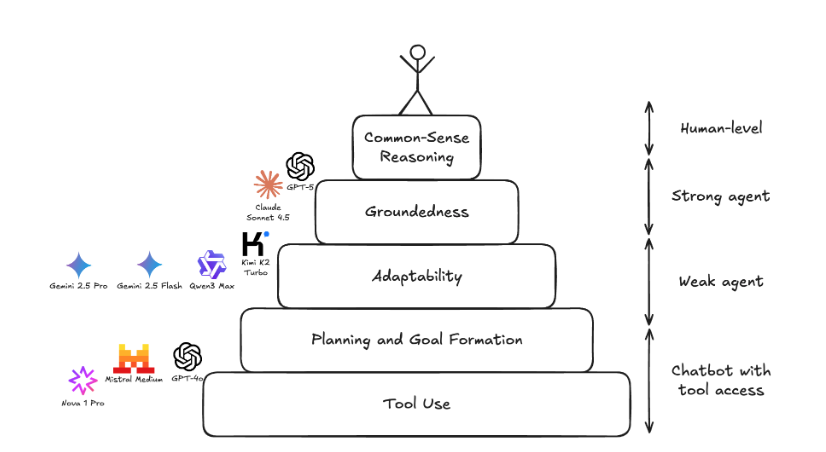
Current Agents’ Abilities Are Far from Human Common Sense
If we categorize agents’ abilities into several levels, current models cannot achieve human-level common sense reasoning:
- Basic tool usage, planning, and goal setting
- Ability to adapt to real-world situations (e.g., handling typos in customer queries correctly)
- Staying grounded in the actual environment (e.g., keeping up with the current date and context of the conversation)
- Common sense reasoning (e.g., in customer service tasks, proactively querying membership levels based on user-provided account information to offer personalized pricing)