大模型背后的数据供应商 - Surge AI
第一次知道Surge AI这家公司是看到Edwin Chen的播客访谈,正值他们第一次出来融资,Edwin的几个观点让人印象深刻
- 不喜欢玩硅谷那套炒作游戏,更倾向于做正确的事而不是看上去很牛逼的事情
- 反对堆人力标数据的做法,专注做最高质量的数据并通过优化流程提高效率
- 指出公开benchmark(例如基于用户偏好的LMArena)并不work
对他们的观点十分赞同,一方面同样不喜欢公式化的创业路径,另外自己有过一段做AutoML的经历,为了提升效果高强度训练过很多模型,深知理解数据对模型效果的重要性。出于对这家公司的兴趣,本文对Surge AI的公司发展、团队、业务情况以及他们的核心观点进行了梳理。
Surge AI公司发展与团队
Surge AI成立于2020年(GPT-3发布后),与大部份硅谷公司的路线不同,创始人Edwin没有拿VC的投资,而是用自己在大厂上班的积蓄创建了公司,而且实现了一开始就盈利。Edwin在访谈中表示自己不喜欢硅谷的status game,融资、炒作、发推特搞圈子等等,而是想自己做一些正确的事情,而且也不希望拿了VC的钱后受制于人。
Surge AI一开始就提供高质量的数据标注(与廉价的大规模众包不同),而且后面新增了RLHF数据和工作流,以及质量控制、复杂rubic设计、领域专家标注、快速实验接口、红队工具等等专业服务,这些服务深度参与了Claude的训练
公司2024年的营收已经超过10亿美元,并在2025年7月第一次计划融资10亿美元,估值在300亿美元左右。
CEO Edwin毕业于MIT,曾在Twitter(搜索/广告质量)、Google、Facebook/Meta 等做过数据科学/机器学习相关工作,对数据有深刻理解。整个公司的团队人数十分精简,核心团队不到100人,专注开发工具链、平台以及构建评估体系等,算上兼职人员和顾问大约250人左右,除此之外Surge AI也会与其他承包商合作完成人力密集的任务。
业务与案例
Surge AI的公开信息不多,在他们的blog中能找到一些案例:
为OpenAI构建的GSM8K数据集(2022)
这是一个包含8500道小学数学题的数据集,都是各种应用题,例如
鲍比拿到工资后,达伦的钱将是鲍比的两倍。鲍比目前有 40 美元,他将获得 16 美元的工资。达伦现在有多少钱?
在这个数据集的构造中,需要考虑到多样性和正确性,详见链接
Claude的训练与评估(2023)
Claude在模型训练与评估中,用到了Surge AI的这些feature:
- 质量控制
- 领域专家的标注
- 快速实验接口
- 红队演练工具
不过没有详细介绍,博客原文
为Meta Superintelligence构建AdvancedIF(2025)
现在的公开benchmark其实和现实场景是脱节的,大家都在关注容易评估的指标(例如数字符)、而不是真正有用的指标。Surge AI在构建这个评估体系的时候遵循以下的原则:
- 构建真正的评估目标,而不是简单的代理目标(例如字符计数很好衡量,但真正的写作能力评估是很困难的)
- 使用人类专家编写的查询数据而非合成数据
- 评估需要足够灵活,而不是当作简单的选择题来处理
- 将复杂的多轮对话作为feature,因为用户在每一轮的对话中也是混乱的
详见原文
除了上面的客户案例之外,Surge AI的blog还有不少有意思的分析,例如金融问题、编程问题的模型评估。在要求制作关于金融风险的PPT以及进行财务预测时,GPT-5、Claude和Gemini都各自会有一些问题,例如出现幻觉、格式错误、公式损坏等等;在SWE-Bench的Bash Only测试中,Gemini 2.5 Pro、Claude Sonnet 4 和 GPT-5都会有幻觉,但各自的幻觉轨迹又截然不同。
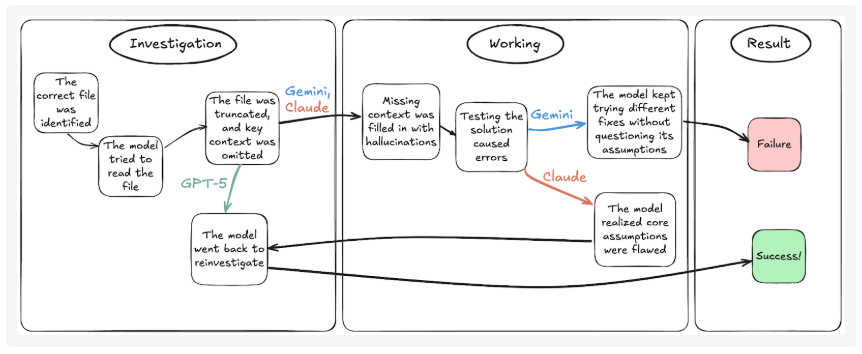
还有一个简单的案例,只是简单的PDF文字提取,ChatGPT和Gemini却都失败了。
核心观点
公开Benchmark有很多问题
例如LMArena:输入一个题目,评估两个答案,然后选出最佳答案
这实际上是面向人类的注意力进行优化,而非面向基本事实,因为普通人并不会去做事实核查,哪个更长或者表情包更炫酷就会投票给谁(ChatGPT也有这个机制),这实际上是很不合理的,但在社区很热门并被奉为圭臬,客户和投资人会参考这个排行榜的表现,迫使开发者面向不合理的评估体系进行优化
除此之外很多其他benchmark也有一堆问题,例如”Humanity’s Last Exam”里面30%的回答都是错误的,HellaSwag中36%的回答是错误的,如果连评估指标都有问题,那训练出来的模型也不会好
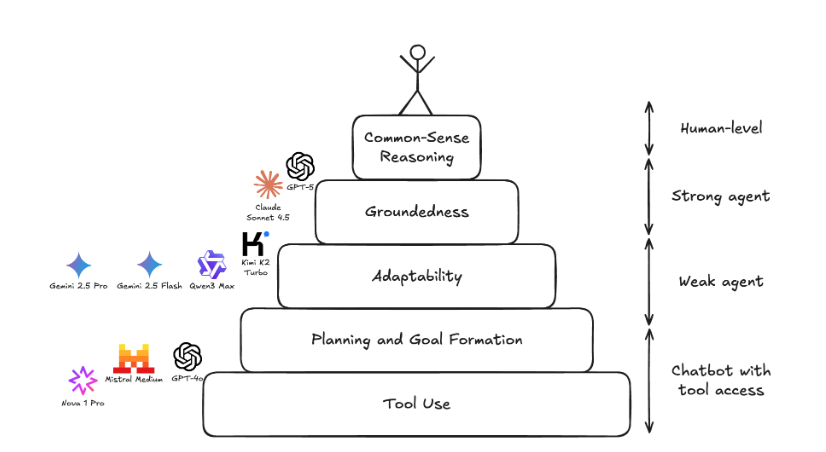
当前Agent的能力与人类常识还差很远
如果将Agent的能力框架分为几个层次,目前的模型都做不到人类级别的常识推理能力:
- 基础的工具使用、规划与目标制定
- 适应现实情况的能力(例如客户查询时打错了字,是否能正确处理)
- 不脱离实际环境(例如紧贴当前对话的日期和上下文)
- 常识推理(例如在客服任务中,根据用户提供的账户信息主动查询会员等级以提供个性化定价)