PyTorch训练加速的量化分析
神经网络的训练往往是整个流程中最花时间的部分,尤其是在一个大型数据集上将随机初始化的神经网络训练到收敛。通常来说,使用更好的硬件平台可以让训练过程变得更快,例如使用更多更好的GPU,使用更大更快的SSD,以及在分布式训练的时候使用InfiniBand替换以太网等等。除了硬件平台之外,软件与算法也同样关键,好的软件平台应该尽可能的充分利用现有硬件平台的资源。本文从一个baseline出发,通过各种方法逐步对训练速度进行优化,我们选取的baseline是在ImageNet数据集上训练ResNet18,总共训练90 epochs,初始计算平台为如表1所示:

1、分析训练过程中的时间瓶颈
我们在这里使用了NVIDIA Tools Extension Library (NVTX)来测量训练过程中各个部分的时间开销,使用方式如下,只需要在训练代码中插入几行代码,然后使用nsys profile python3 main.py启动训练即可,最后会生成一个.qdrp文件,我们在这里分别统计了一个batch中数据加载,前向传播,反向传播,以及梯度下降所花费的时间,为了节省时间我们对300个batch的训练过程进行了统计。
import torch.cuda.nvtx as nvtx
nvtx.range_push("Batch 0")
nvtx.range_push("Load Data")
for i, (input_data, target) in enumerate(train_loader):
input_data = input_data.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
nvtx.range_pop(); nvtx.range_push("Forward")
output = model(input_data)
nvtx.range_pop(); nvtx.range_push("Calculate Loss/Sync")
loss = criterion(output, target)
prec1, prec5 = accuracy(output, target, topk=(1, 5))
optimizer.zero_grad()
nvtx.range_pop(); nvtx.range_push("Backward")
loss.backward()
nvtx.range_pop(); nvtx.range_push("SGD")
optimizer.step()
nvtx.range_pop(); nvtx.range_pop()
nvtx.range_push("Batch " + str(i+1)); nvtx.range_push("Load Data")
nvtx.range_pop()
nvtx.range_pop()
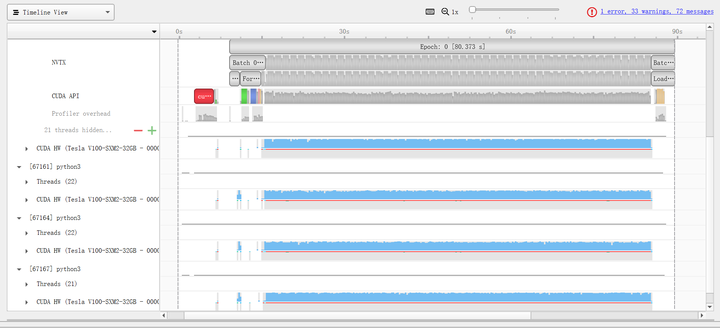
在使用baseline代码进行训练的时候,我们使用Nvidia Nsight Systems对生成的.qdrp文件进行可视化,结果如图1所示,可以看到训练300个batch所用时间为336.524s,但值得注意的是,CUDA内核实际运行的时间仅仅占用了总时间的约四分之一,而四分之三的时间都在进行数据加载,在这个过程中CUDA内核和CPU使用率几乎为0,这成了我们使用baseline代码进行训练的过程中的性能瓶颈。
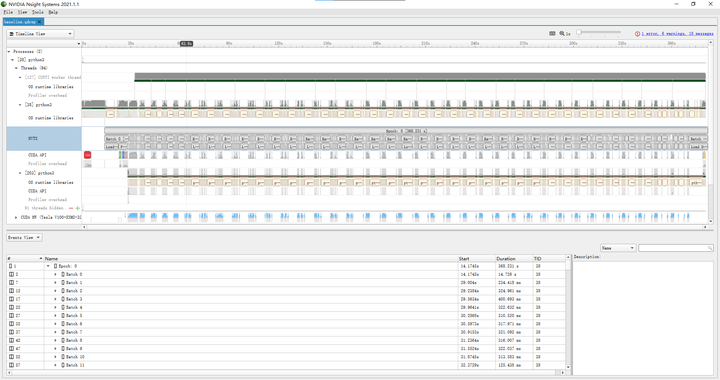
如果进一步查看每个batch里面的训练时间(例如batch 122),可以看到将数据从Host内存传到Device显存所用时间为13.6ms(数据大小为 224*224*3*256*4=154,140,672bytes,带宽11.3GB/s);forward中调用CUDA内核所用时间为15.4ms,CUDA内核实际运行时间为67.3ms;backward中调用CUDA内核所用时间为19.9ms,CUDA内核实际运行时间为164.7ms;SGD中调用CUDA内核所用时间为8.0ms,CUDA内核实际运行时间为1.8ms。
2、加速数据读取
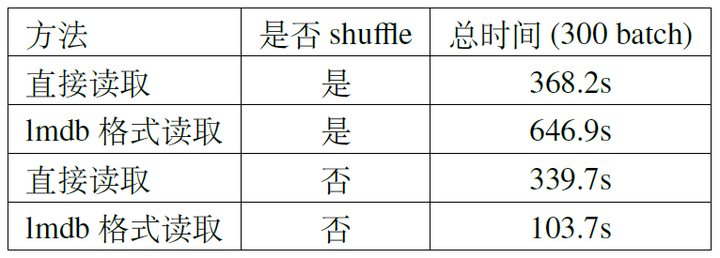
从上一节的实验结果可以看出来,整个训练过程中四分之三的时间都花在了数据读取上,而这个过程中的CPU/GPU使用率都几乎为0,造成了硬件资源上的浪费,因此我们首先对I/O部分进行优化。baseline训练代码数据读取慢主要是因为PyTorch在训练的时候读取的是一张张.jpeg等格式的原始图片,不仅需要解码,而且读取过程并不连续,cache miss较多从而I/O时间会很长;而Tenorflow等框架会有自己的.tfrecord格式,类似的还有hdf5,lmdb等,这些格式将整个数据集存储在一个大的二进制文件中,从而在读取数据的时候可以进行连续读取,效率会高很多。
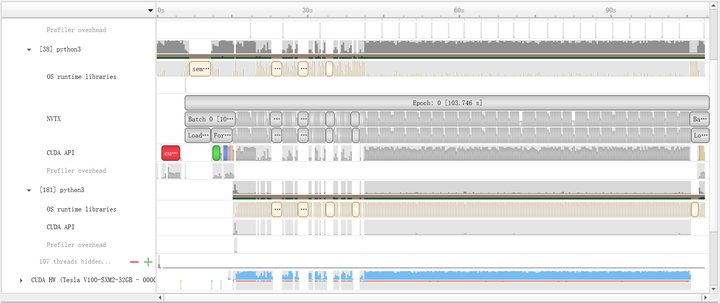
在优化I/O的时候需要根据硬件环境的不同选取合理的方案,若计算平台的内存不足以容纳整个数据集可以使用lmdb(hdf5需要将整个文件加载进内存)。我们做了两组实验进行对比,分别是随机读取(shuffle训练数据)和连续读取(不shuffle训练数据)的情况,结果如表2所示。如果不对数据集做shuffle,那么用lmdb读取的速度会非常快,profile的结果如图2所示,在训练了约50个batch之后,CUDA内核几乎一直处于忙碌状态,这得益于连续读取所减小的cache miss率;但是在shuffle的情况下反而会变得更慢。
若内存足够大可以直接简单粗暴的将整个数据集直接放到内存中,具体则可以通过挂载tmpfs文件系统,然后将整个数据集放到该文件夹中来实现。如果没有挂载的权限也可以将数据集放到/dev/shm目录下,同样也是tmpfs文件系统,通常160G的大小足够容纳整个ImageNet数据集。
# 有挂载权限
mkdir -p /userhome/memory_data/imagenet
mount -t tmpfs -o size=160G tmpfs /userhome/memory_data/imagenet
root_dir="/userhome/memory_data/imagenet"
# 无挂载权限
mkdir -p /dev/shm/imagenet
root_dir="/dev/shm/imagenet"
mkdir -p "${root_dir}/train"
mkdir -p "${root_dir}/val"
tar -xvf /userhome/data/ILSVRC2012_img_train.tar -C "${root_dir}/train"
tar -xvf /userhome/data/ILSVRC2012_img_val.tar -C "${root_dir}/val"
将数据集放到tmpfs文件系统后,我们重新用baseline代码进行了训练,结果如图3所示,CUDA内核几乎一直处于满负荷的状态,整体的训练时间也从baseline的336.524s缩短到87.989s(仅为baseline的 26%),提速效果非常明显。
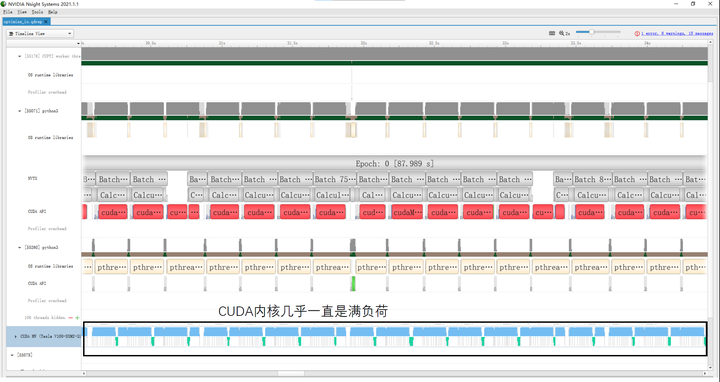
然后同样的,我们进一步统计每个batch里面的训练时间,将数据从Host内存传到Device显存所用时间为15.4ms(1.8ms ↑ );forward中调用CUDA内核所用时间为7.9ms(7.5ms ↓ ),CUDA内核实际运行时间为67.5ms(0.2ms ↑ );backward中调用CUDA内核所用时间为16.6ms(3.3ms ↑ ),CUDA内核实际运行时间为164.3ms(0.4ms ↑ );SGD中调用CUDA内核所用时间为5.5ms(2.5ms ↑ ),CUDA内核实际运行时间为1.9ms(0.1ms ↑ )。可以看出计算上所花的时间与baseline几乎没有区别。
3、混合精度训练
从上一节可以看出,在优化数据读取之后CUDA内核可以处于满负荷的状态,因此要进一步加速训练只能从计算速度(主要是forward与backward)本身来入手,但PyTorch使用了CUDNN的kernel进行计算,因此我们没法优化kernel本身,只能通过将部分FP32的计算转换为FP16来进行提速,即混合精度训练\cite{micikevicius2017mixed}。
混合精度训练一种比较简便的方案是使用Apex (A PyTorch Extension),仅需要在原代码中添加几行代码即可,并且还可以选择不同的FP16训练方案。
from apex import amp, optimizers
# Allow Amp to perform casts as required by the opt_level
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
...
# loss.backward() becomes:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
...
其中的opt_level有多种选择,O0是全部使用FP32进行训练,O1在部分操作上使用FP16进行计算,O2在绝大部分操作上使用FP16进行计算,O3则是全部使用FP16进行计算。在使用O1与O2时,FP16的算子(卷积,全连接等)使用FP16进行前向传播与反向传播,但维护了一个FP32的权重用于梯度下降时的更新(图4),FP32的算子(BN等)则使用了FP32进行前向传播与反向传播,注意这两种算子都使用了FP32进行梯度下降。使用FP16进行训练有一定的风险会训练发散,具体选择哪一种方案需要根据实际情况在提速与防止训练发散之间进行权衡。我们在上一节中速度最快方案的基础上进一步对FP16训练做了实验,结果如表3所示,可以看出利用FP16进行训练的时候forward与backward的速度相比FP32有明显提升,总体训练时间也有较为明显的下降。
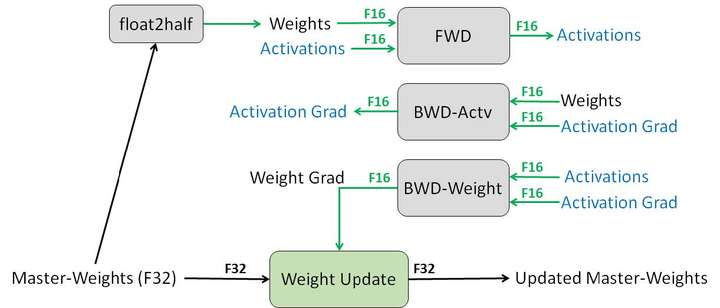
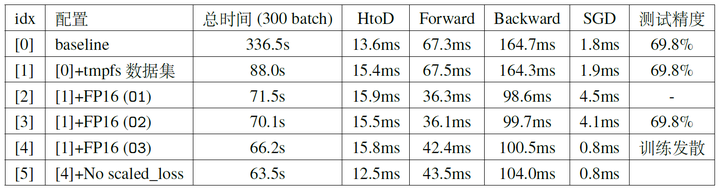
到本节为止,我们一直使用单个GPU进行训练,神经网络的训练速度被各种方法一步步加快,首先从baseline的336.524s开始(图1),在优化I/O之后加速为87.989s(图3),之后再通过使用混合进度训练在不减小精度的情况下加速到70.1s。
4、单机多卡并行训练
本节将在优化数据读取以及混合进度训练的基础上,使用单机多卡并行训练进一步加速,目前仅关注于数据并行,暂不考虑模型并行甚至算子并行的方法。
在PyTorch上实现单机多卡训练通常有两种方式,一种是使用nn.DataParallel,另一种是使用nn.parallel.DistributedDataParallel。前者只使用了单个进程;而后者使用了多个进程并行训练,同样也适用于多机多卡,除了nn.parallel.DistributedDataParallel之外还有一些第三方库可以用于PyTorch的多进程并行训练,例如APEX,Horovod等。
使用nn.DataParallel是最为简单的一种方式,仅用一行代码就可以实现:
model = torch.nn.DataParallel(model)
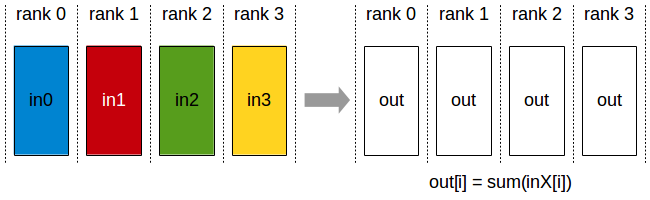
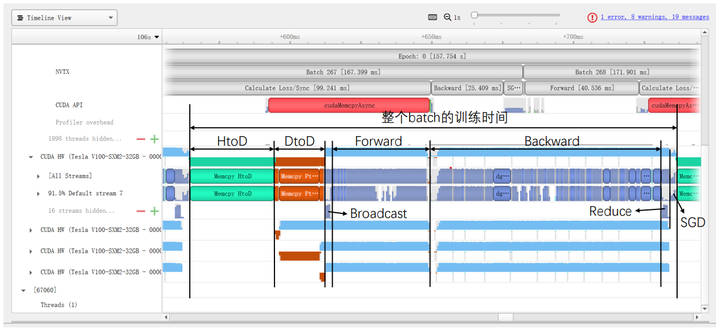
在使用nn.DataParallel进行并行训练时,首先会将整个batch的数据加载到一张主GPU上;然后再通过PtoP的拷贝将每份数据(BS/GPU_NUM)从主GPU依次拷贝到其他GPU上;之后再通过NVIDIA Collective Communications Library (NCCL)的Broadcast(图5)将神经网络的参数从主GPU广播给其他GPU;然后每张GPU上各自进行前向传播与反向传播;最后再通过Reduce(图6)将其他GPU上的梯度归约到主GPU上,主GPU进行梯度下降得到优化后的神经网络。
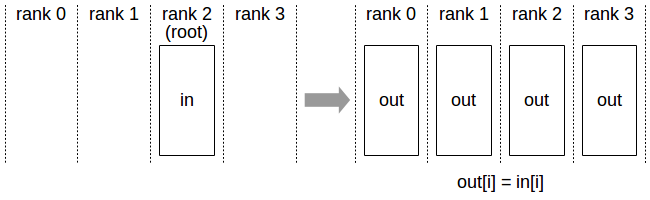
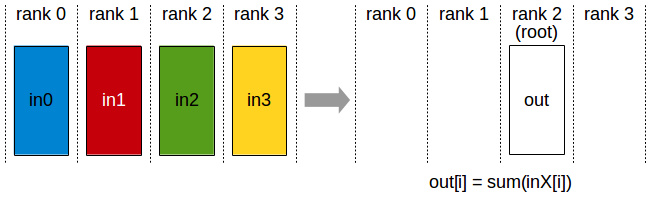
我们首先在配置[1]的基础上进行实验,并使用相同的batch size(例如总batch size为256时,使用双卡的时候每张卡128,四卡的时候每张卡64),结果如以表4所示(实验中迭代了500个batch,中间300个batch的总时间作为表4中的总时间;DtoD的时间包含两部分,分别是主GPU将每份数据PtoP传给其他GPU的时间,以及主GPU Broadcast神经网络参数和各个GPU将梯度Reduce到主GPU的时间总和)。其中BS=512时[7]的profile结果如图7所示
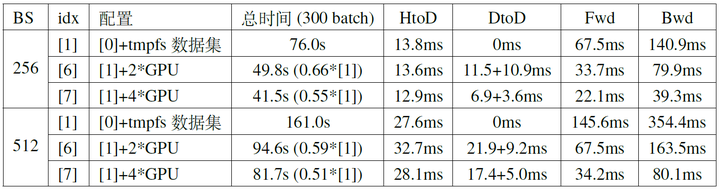
从上面的表4和图7中大概可以观察到以下几个现象:
- 使用多GPU可以有效减小forward与backward的时间。
- GPU数量增加到一定程度时,GPU运算完成之后会出现等待数据加载的情况。
- 随着GPU数量的增加,GPU之间通讯所花的时间占比变大,GPU数量对于整体速度的提升越发有限。
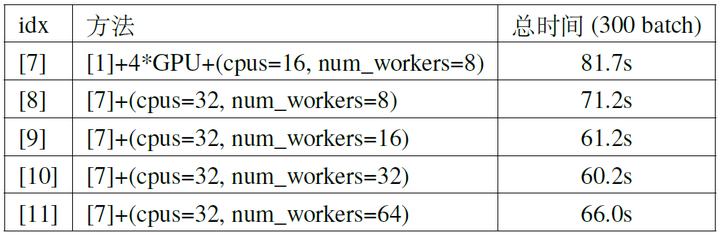
对于其中的第二条,数据加载的时间主要由两部分构成,一方面是I/O的时间,这方面我们已经通过将数据集放进内存中解决掉了;另一方面则是数据预处理的时间,这方面我们可以通过增加cpu的线程数以及数据读取的线程数来解决,在docker容器中训练的时候可以尝试前者的方法,通过修改docker run时–cpus的参数来实现,后者则可以通过在创建torch.utils.data.DataLoader对象时适当增加num_workers的大小来实现。我们在[7]的配置上进一步改进,在BS=512时的实验结果如表5所示,可以看出如果训练过程中GPU还存在等待数据的空闲,适当增加CPU线程数与数据加载的线程数可以有效减小总的时间(主要是通过减小GPU等待数据的空闲来实现的),但过度增大CPU线程数会造成一定程度的浪费,因为到了一定程度时GPU等待数据的空闲已经很小了,除此之外过度增加线程数也会由于线程本身的开销过大而变得更慢(例如下表的[10]与[11])。
而对于第三条,我们注意到nn.DataParallel并行训练时会先将所有数据从内存传到一张主GPU上,然后再将数据从主GPU依次PtoP传到其他GPU上,该过程显然不如直接将每一份数据从内存传到对应的GPU上更加高效,这可以节省掉将每份数据从主GPU依次PtoP传到其他GPU上的时间(表5中DtoD耗时的前一部分,在配置[7]的情况下这部分时间占比接近20%)。除此之外,nn.DataParallel在每一次迭代时都会先将模型的参数从主GPU上Broadcast到其他GPU上,最后再将梯度Reduce到主GPU上。如果利用All-Reduce将归约之后的梯度传到每个GPU上(图8),那么每个GPU上可以各自进行梯度下降,这样便省去了nn.DataParallel最开始Broadcast模型参数的时间开销(大概占比2%)。
基于多进程并行的nn.parallel.DistributedDataParallel实现了这样的方法,具体如何使用可以参考官方的example。我们在配置[10]的基础上进行了实验,结果如表6所示,使用DistributedDataParallel时的DtoD时间由于不同GPU之间的同步时间具有较大波动,因此没有进行统计,可以看出使用DistributedDataParallel可以减小约1/3的时间。从profile结果中(图9)可以看出配置[12]的CUDA内核使用率远高于配置[7],这一方面是由于我们使用了更多的CPU线程和数据加载线程,另一方面是由于使用了基于多进程实现的并行训练,相比多线程的实现可以突破Python的GIL(Global Interpreter Lock),从而进一步提升效率。

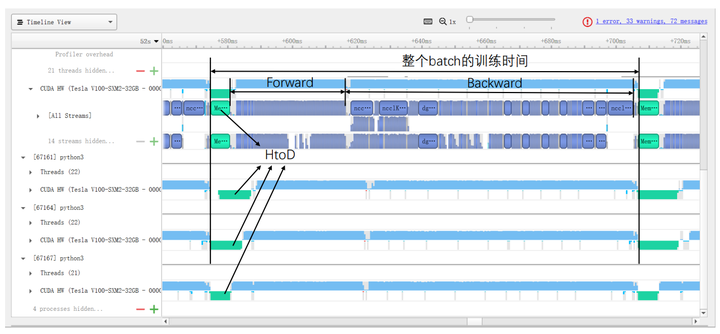
具体来看,图10与图11分别展示了使用DataParallel和DistributedDataParallel时训练某个batch的具体时间开销。在使用DistributedDataParallel时,图9中HtoD的数据大小从总BS减小到BS/GPU_NUM,这部分时间理论上可以减小为DataParallel的1/GPU_NUM(不同GPU的传输速度略有波动);除此之外,DtoD的时间可以完全节省掉;最后Broadcast和Reduce的时间被All-Reduce所替代(由于All-Reduce需要所有GPU的同步,耗时波动较大)。这两种方法在具体计算上的耗时(Forward/Backward/SGD)没有明显区别。
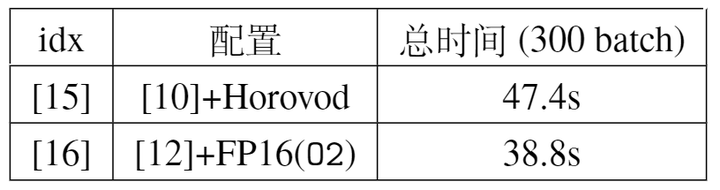
除了DistributedDataParallel之外,我们之前提到还有APEX和Horovod等第三方库实现了同样的多进程并行,我们同样也使用这两种第三方库进行了对比实验,结果如表7所示。可以看出三种实现方式的速度差别不大,值得注意的是APEX可以对BN进行同步运算,也就是在BN层计算batch的均值/标准差的时候对所有GPU上的数据进行同步,这样计算得到的均值/标准差是由整个batch的数据统计而来,而非单张GPU上的一份数据得到,通过这样的方式可以使训练更加稳定。但这样的方式需要每次计算均值/方差时所有GPU进行同步(sync),因此会带来一些额外的时间开销,但从profile的结果来看,GPU之间计算不同步的主要原因是最初的HtoD时间不同,在经过第一个BN层同步之后,后续的BN层所需要的同步时间是很短的(前提是所有GPU的算力基本相同)。
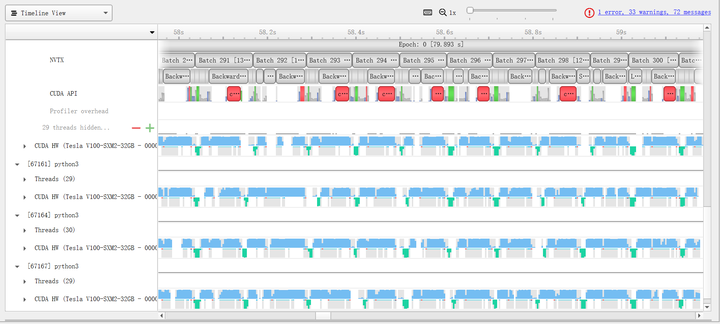
最后再将上节的FP16混合精度训练与本节的多卡训练方法相结合,通过将这两种正交的加速方式相结合,我们可以将训练速度提升到极限。具体来说,从表8可以看出使用DistributedDataParallel是并行效率最高的,因此可以将其与FP16(O2)相结合,实验结果表明该方法可以进一步加速到38.8s,实验的profile结果如图12所示。
5、多机多卡并行训练
前面的实验都是在单个机器上进行的,但在实际情况中为了加速还需要进行多机多卡的分布式训练,例如双机四卡的情况下可以用以下的代码进行训练:
# 假设在2台机器上运行,每台可用卡数是4
# 机器1:
python -m torch.distributed.launch --nnodes=2 --node_rank=0 --nproc_per_node 4 \
--master_adderss $my_address --master_port $my_port main.py
# 机器2:
python -m torch.distributed.launch --nnodes=2 --node_rank=1 --nproc_per_node 4 \
--master_adderss $my_address --master_port $my_port main.py
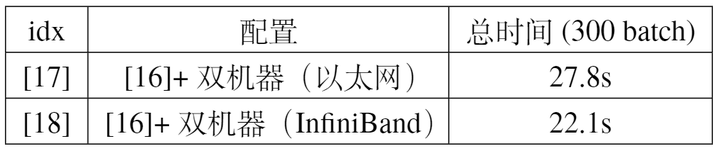
我们分别在不同硬件配置下进行了训练速度的测试,主要区别在于是否使用InfiniBand,实验结果如表9所示,由于在训练过程中不同机器上的数据需要同步,因此在训练耗时中有一部分来源于机器之间的通讯时间,使用InfiniBand可以达到比以太网更低的时延(但以太网通用性更好,InfiniBand相对比较适用于并行计算的场景)。
6、总结
本文中通过调整配置一步步对训练进行优化,尽可能充分利用gpu的算力。首先在使用baseline代码,单个GPU,BS=512的情况下训练300batch的速度为161.0s(配置【0】);然后直接使用DataParallel在4张GPU上进行训练,可以加速为81.7s(配置【7】);之后再增加一定的CPU线程数与数据加载线程数,通过提升数据加载速度加速为60.2s(配置【10】);除此之外再将DataParallel替换为DistributedDataParallel,通过减小GPU之间通讯时间加速为41.6s(配置【12】);然后再与混合精度训练相结合,加速到38.8s(配置【16】);最后再使用两台这样的节点通过InfiniBand通讯进行并行训练,加速到22.1s(配置【18】)。