Designing Compact Networks: Taking Convolution Apart
The classic networks (AlexNet, VGG, Inception, ResNet, SENet, …) were mostly built to chase accuracy. But to actually deploy — smaller runtime memory, lower latency, higher throughput — you need architectures designed to be compact. This post walks through several design threads.
MobileNet: depthwise separable convolution
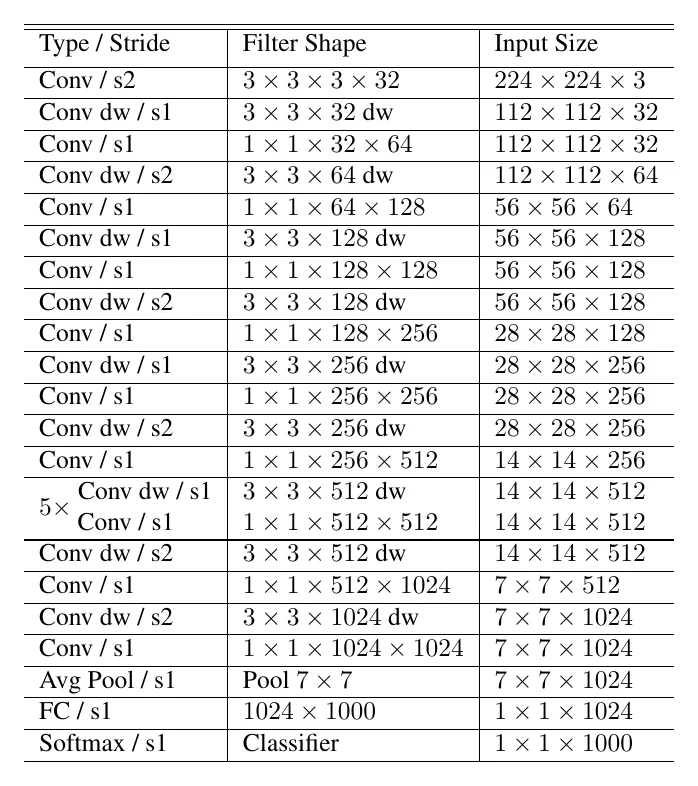
MobileNet is more or less where compact design begins. As the name implies, it targets mobile deployment, and its key contribution is splitting standard convolution into two steps: depthwise convolution and (pointwise) convolution.
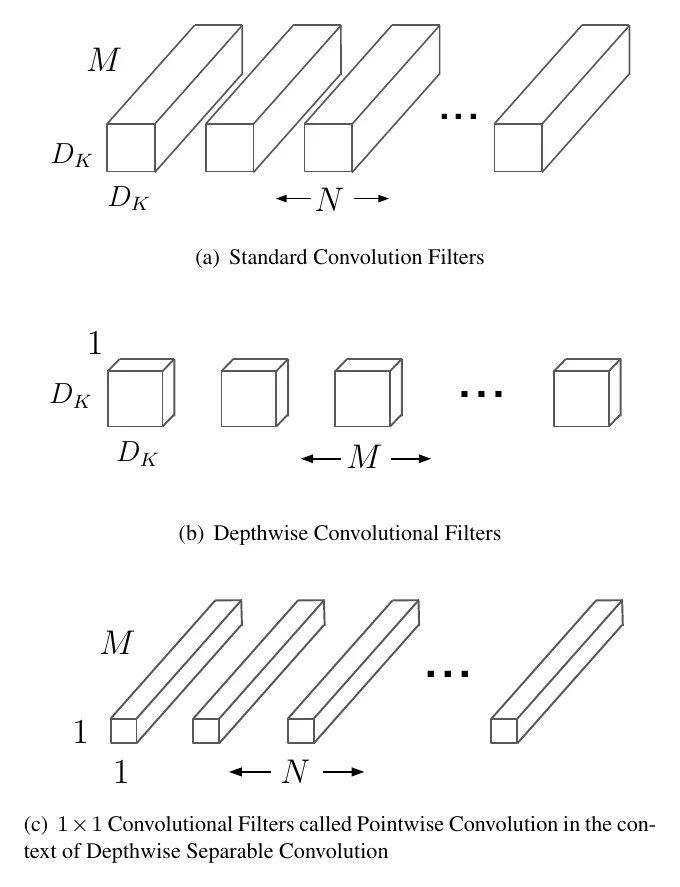
Let’s quantify it. Say we turn a tensor into with kernel size . Standard convolution’s FLOPs:
After splitting into depthwise + :
Their ratio is:
For the most common kernel (), when output channels are large this split cuts conv FLOPs to as little as of standard convolution. But note: 9× fewer FLOPs ≠ 9× faster in practice — inference frameworks usually implement convolution via im2col+GEMM or Winograd, and depthwise convolution doesn’t really reduce memory access, so the measured speedup is quite limited. The parameter analysis is analogous, with the same ratio ; the parameter reduction is more “real” than the FLOPs one, since it genuinely saves disk space — unlike FLOPs, whose reduction is bottlenecked by the software implementation.
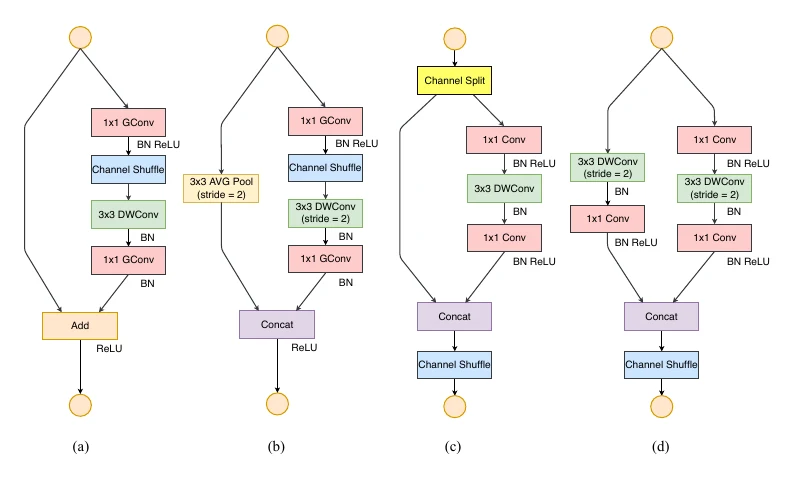
ShuffleNet: grouped 1×1 convolution + channel shuffle
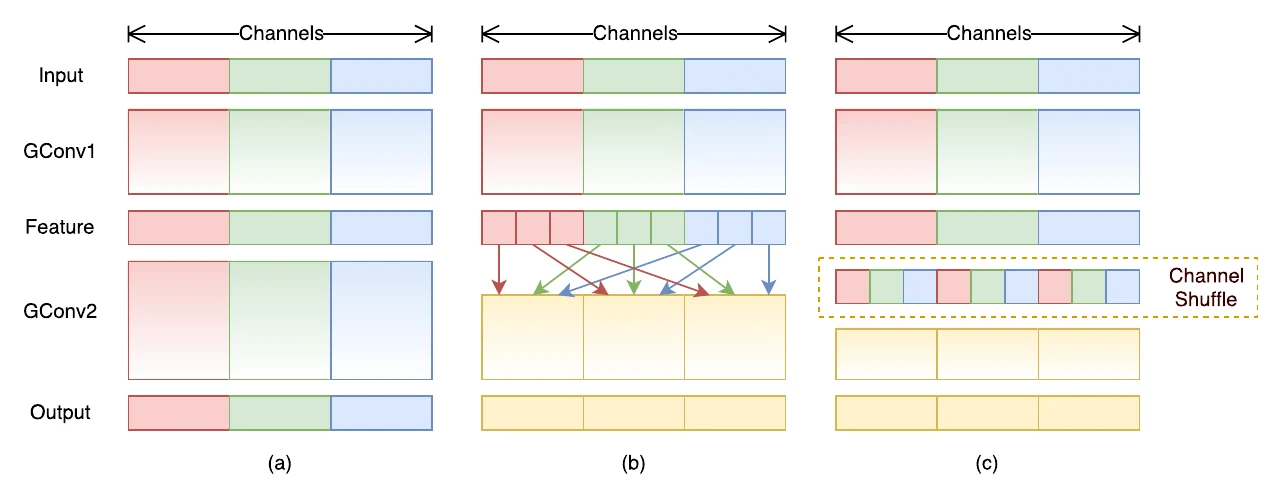
ShuffleNet arrived a few months after MobileNet and goes further at the convolution: besides keeping the depthwise conv, it also groups the standard conv, then adds channel shuffle so information across groups can fuse in the next layer. Note channel shuffle isn’t a true random permutation — in PyTorch it’s implemented with reshape + permute.
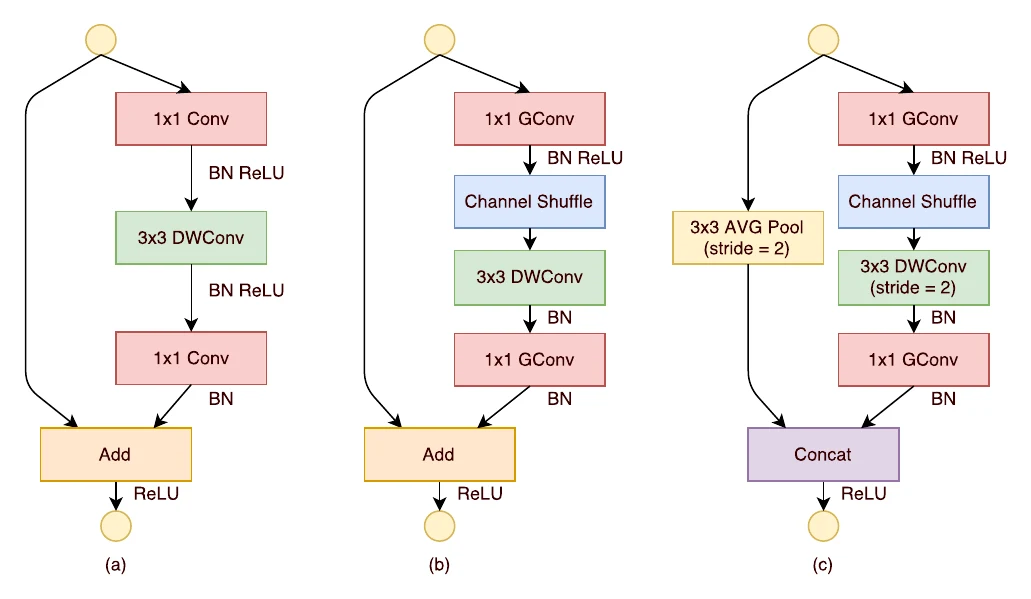
ShuffleNet stacks many blocks:
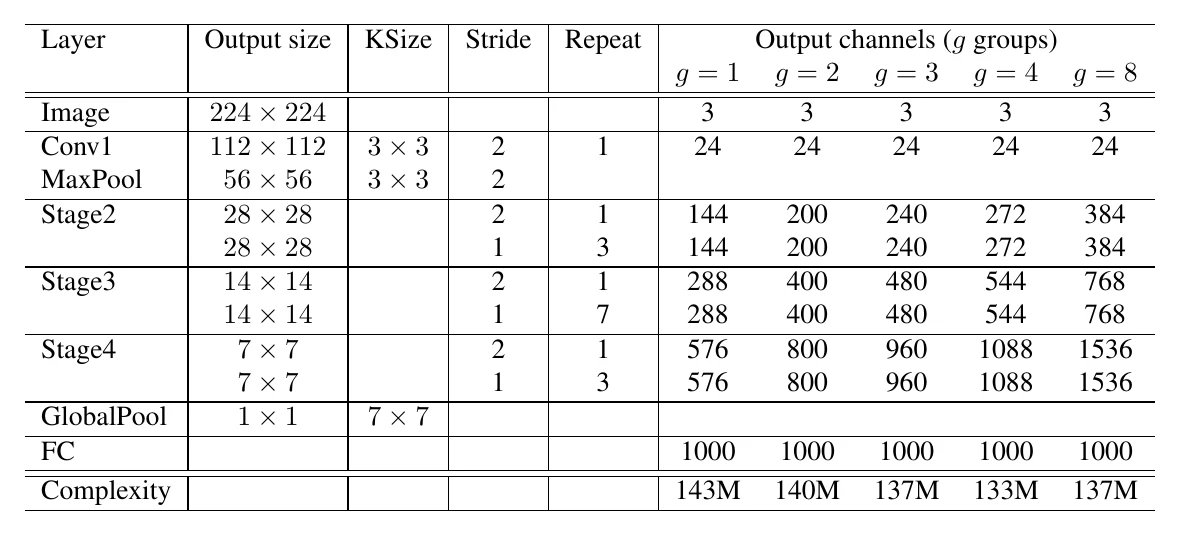
Quantitatively: channel shuffle itself doesn’t change FLOPs or parameters, but it changes the feature map’s memory layout, adding strided memory access for the next layer. A grouped conv with groups has FLOPs — both FLOPs and parameters drop to of a standard conv. At fixed total FLOPs, more groups means you can use more filters; getting the best accuracy means trading off carefully between the two.
MobileNetV2: Inverted Residual
MobileNetV2 folds ResNet’s residual connection and bottleneck into MobileNet, but with an inverted bottleneck: a conv first expands the channels, then a depthwise conv operates, then a second conv brings the channels back down to the input size.
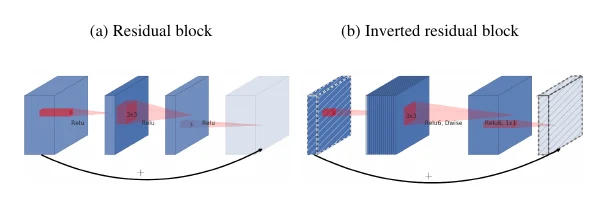
It invents no new compact operation; instead it folds capacity-boosting ideas (residual connections, bottlenecks) into a compact network, pushing accuracy further. Notably, MobileNetV2 later became the backbone for many architecture-search methods (both MobileNetV3 and EfficientNet below build on it).
ShuffleNetV2: four rules from memory-access cost
ShuffleNetV2 focuses on an often-overlooked metric — memory-access cost (MAC) — and derives four design rules for compact networks.
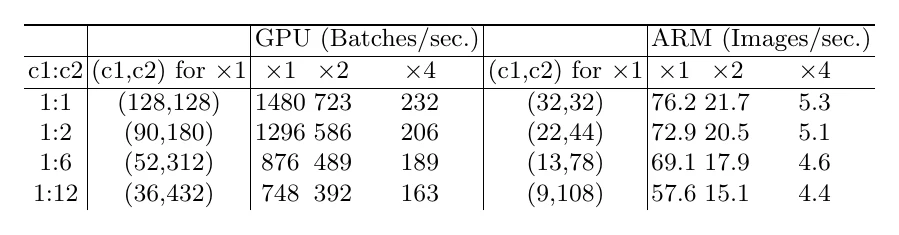
Rule 1: keep a conv’s input and output channels equal. For a conv with input/output channels over an map, . At fixed FLOPs, the memory-access cost
By the AM-GM inequality, MAC has a lower bound, reached when . Experiments confirm it: at the same FLOPs, a input/output channel ratio is fastest (the same on GPU and ARM).
Rule 2: too many groups increases MAC. For a grouped conv with groups:
At fixed FLOPs, MAC grows with .
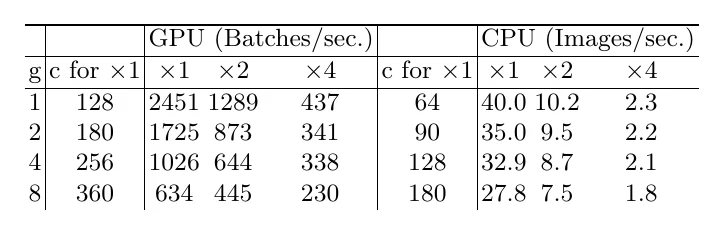
Rule 3: too much fragmentation hurts parallelism. Many small serial/parallel branches weaken parallel computation. But deeper structures often give higher accuracy, so it’s a trade-off between accuracy and parallel speedup.
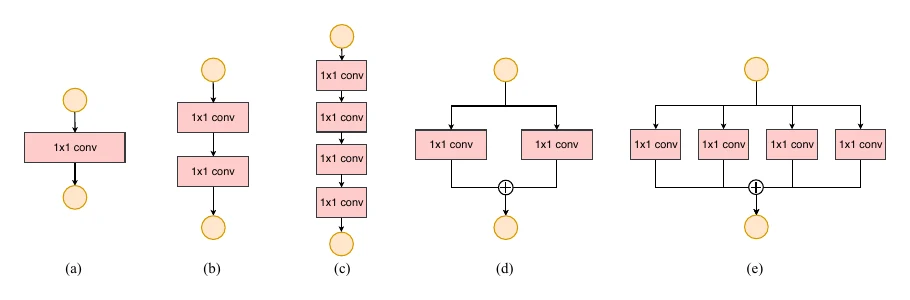
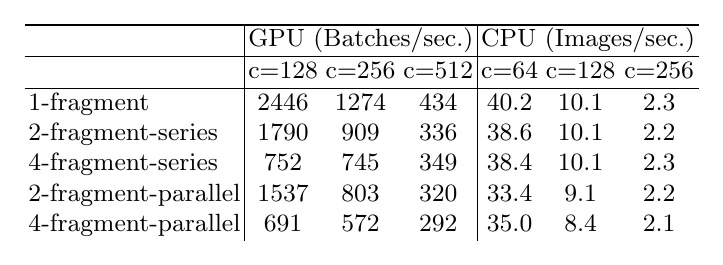
Rule 4: don’t ignore the cost of element-wise operations. An operation’s time has two parts, MAC and FLOPs. For convolution, FLOPs far exceeds MAC; but for low-FLOPs operations like element-wise add and ReLU, MAC is the dominant cost and can’t be ignored.
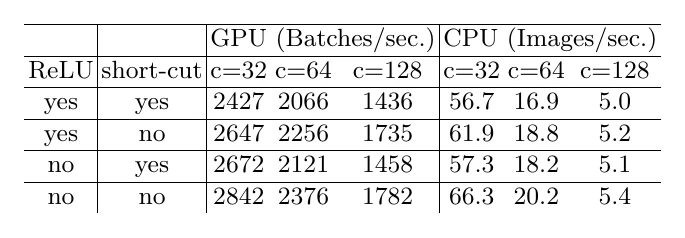
Following these, ShuffleNetV2’s block is almost entirely different from V1’s: no more grouped convs, replaced by channel split (keeping the residual connection without the extra MAC of grouped convolution — Rule 2); and the block’s Channel Split, Concat, and Channel Shuffle can fuse into one operation to cut MAC (Rule 4).
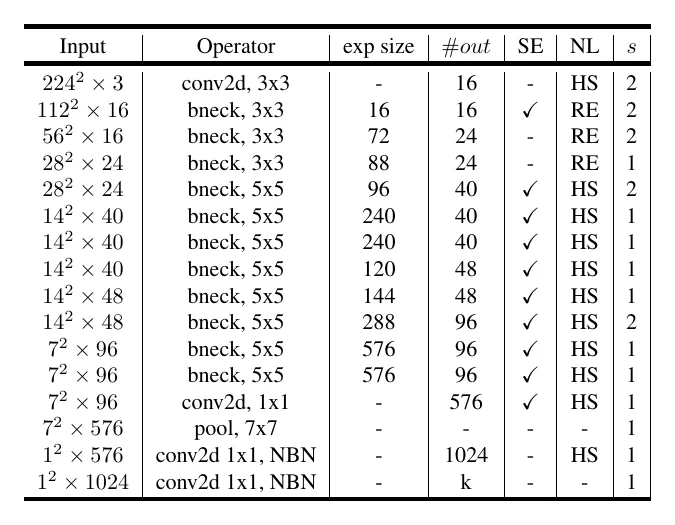
MobileNetV3: h-swish
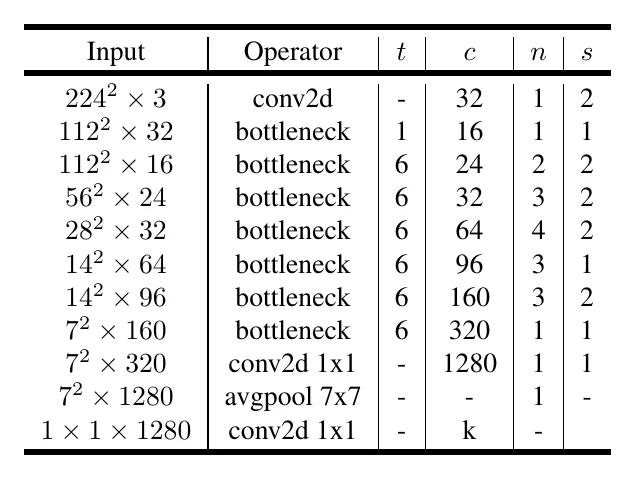
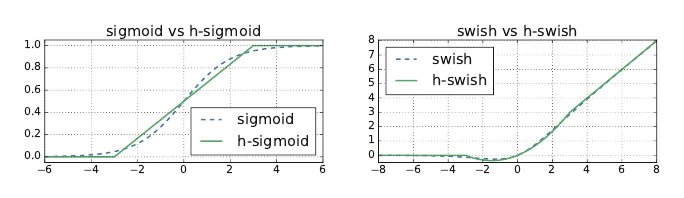
MobileNetV3 is derived from MobileNetV2 via automated search (MnasNet + NetAdapt compression), mainly tweaking the number of conv layers, kernel sizes, channels, and adding SE modules in some layers. It also swaps ReLU for hard-swish in deeper layers:
The original swish is , but sigmoid is expensive; hard-swish approximates it for nearly the same effect at far lower cost.
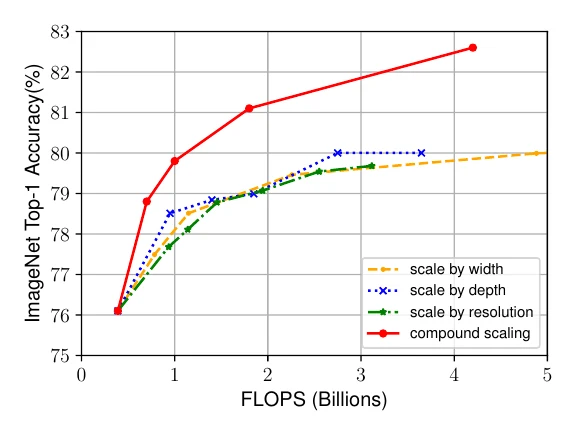
EfficientNet: compound scaling
EfficientNet arrived around the same time as MobileNetV3, also searched on top of MnasNet, but its search used only simple grid search. Its core is a network scaling method: if a compact network reaches decent accuracy at small FLOPs, then for higher accuracy just scale it up. Scaling spans three dimensions: width, depth, and input resolution.
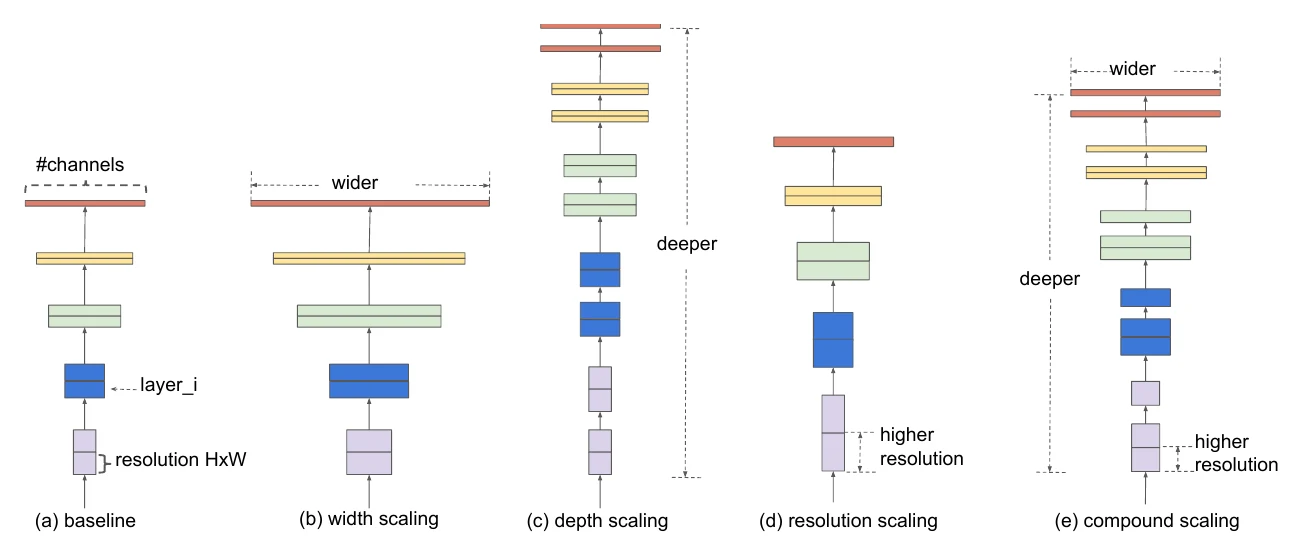
Each dimension’s scale factor decouples into a relative factor and a global factor :
The constraint exists because FLOPs grow quadratically with width and resolution but linearly with depth; fixing to a constant keeps FLOPs controllable under any scaling. During search, fix and grid-search the best ; afterward, dialing scales the network to any FLOPs level.
GhostNet: cheap “ghost” features
GhostNet also takes a decomposition route, but from a distinctive observation: visualizing feature maps shows that many channels are very similar to one another — so there’s no need to compute them all with expensive standard convolution.

So GhostNet splits standard convolution into two steps: first compute part of the output with fewer standard-conv filters, then “generate” the rest from it via cheap operations (linear transforms / depthwise convs), and concat the two parts.
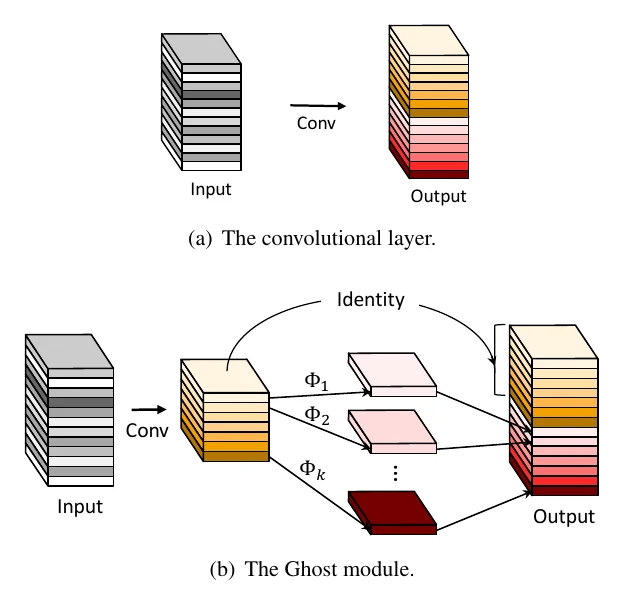
Quantitatively: with kernel , input channels , and output , standard convolution has FLOPs . If the Ghost module computes channels in the first step, uses a depthwise conv of size for the cheap ops, and sets , the speedup is
(the approximations use and ). The parameter compression ratio is also roughly .
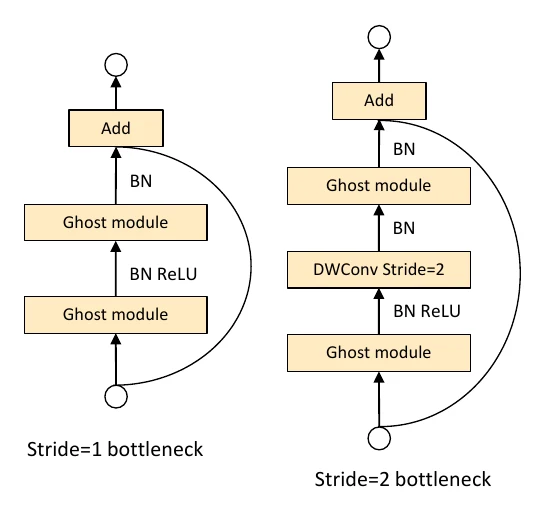
From MobileNet taking convolution apart, to ShuffleNetV2 watching memory access, to GhostNet reusing similar features — the through-line of compact design is endlessly trading off FLOPs, memory access, and accuracy. And MobileNetV3 and EfficientNet already replace “humans designing” with “automatic search” — which is exactly the direction of neural architecture search (NAS).
References
- Howard, Andrew G., et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv:1704.04861, 2017.
- Zhang, Xiangyu, et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. CVPR, 2018.
- Ma, Ningning, et al. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. ECCV, 2018.
- Sandler, Mark, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks. CVPR, 2018.
- Howard, Andrew, et al. Searching for MobileNetV3. arXiv:1905.02244, 2019.
- Tan, Mingxing, Le, Quoc V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv:1905.11946, 2019.
- Han, Kai, et al. GhostNet: More Features from Cheap Operations. CVPR, 2020.
- Tan, Mingxing, et al. MnasNet: Platform-Aware Neural Architecture Search for Mobile. CVPR, 2019.
- Jia, Yangqing, et al. Caffe: Convolutional Architecture for Fast Feature Embedding. ACM MM, 2014.
- Lavin, Andrew, Gray, Scott. Fast Algorithms for Convolutional Neural Networks (Winograd). CVPR, 2016.