紧凑网络结构设计:把卷积拆开
经典网络(AlexNet、VGG、Inception、ResNet、SENet 等)大多是为”刷精度”而生。但要真正落地——更小的运行内存、更低的时延、更大的吞吐——就需要专门设计的紧凑网络结构。这篇梳理几条主线的设计思路。
MobileNet:深度可分离卷积
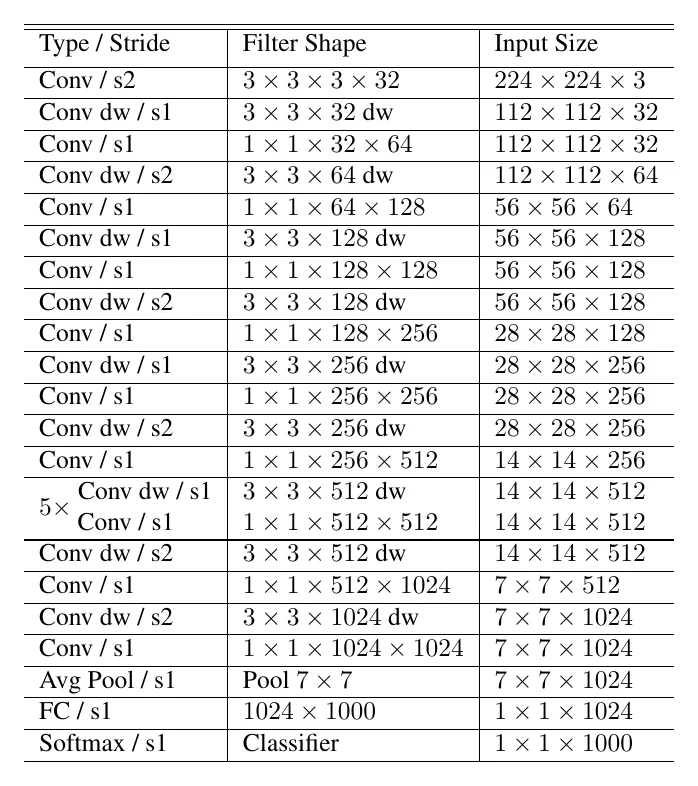
MobileNet 几乎是紧凑网络设计的起点。顾名思义,它面向移动端部署,最大的贡献是把传统卷积拆成两步:深度可分离卷积(depthwise convolution) 和 卷积(pointwise convolution)。
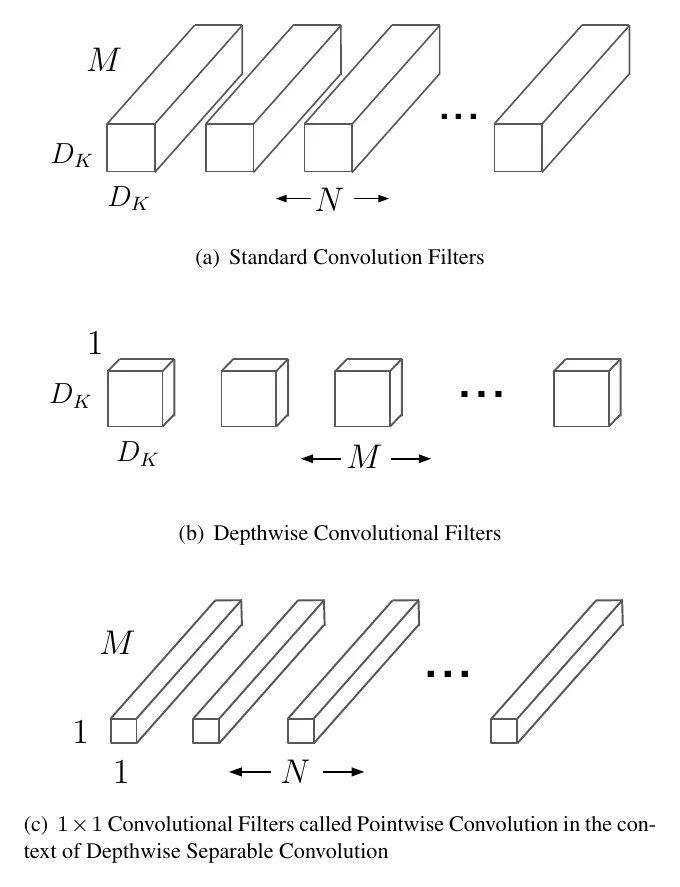
可以定量分析一下。设把 的张量经卷积变成 ,卷积核大小 。标准卷积的 FLOPs 为:
拆成深度可分离 + 之后:
两者之比为:
最常用的是 卷积(),当输出通道 较大时,这种拆分相比标准卷积最多能把 FLOPs 降到 。但要注意:FLOPs 降 9 倍不等于实测快 9 倍——推理框架对卷积通常用 im2col+GEMM 或 Winograd 实现,而深度可分离卷积并不能有效降低访存开销,所以实测提速其实很有限。参数量的分析同理,比值也是 ;参数量的减小比 FLOPs 更”实在”,因为存到磁盘时确实省空间,不像 FLOPs 受制于软件实现而难有实质加速。
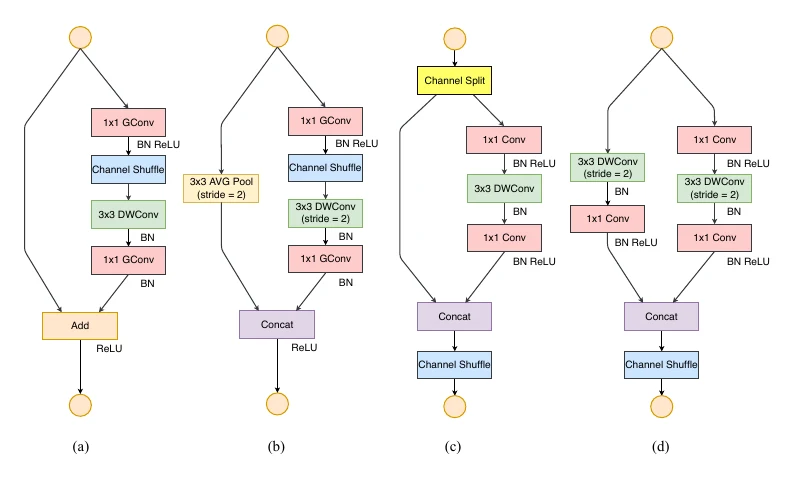
ShuffleNet:分组 1×1 卷积 + channel shuffle
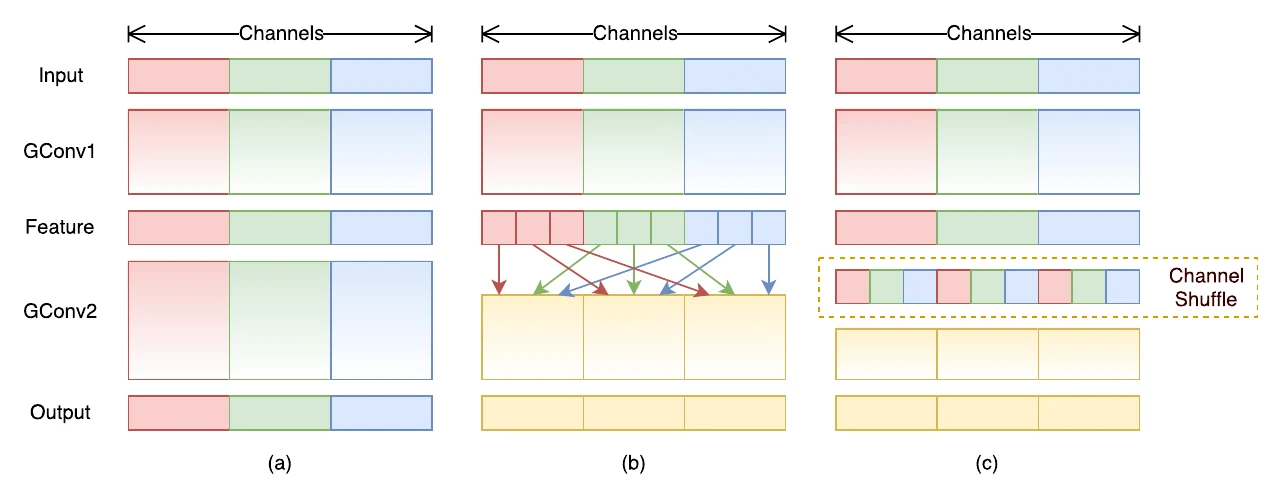
ShuffleNet 比 MobileNet 晚几个月,它进一步对 卷积下手:除了沿用深度可分离的 卷积,还把标准的 卷积也分组,并在分组之后引入 channel shuffle,让各组通道的信息能在下一层融合。注意 channel shuffle 并不是真随机打乱——以 PyTorch 为例,它是用 reshape + permute 实现的。
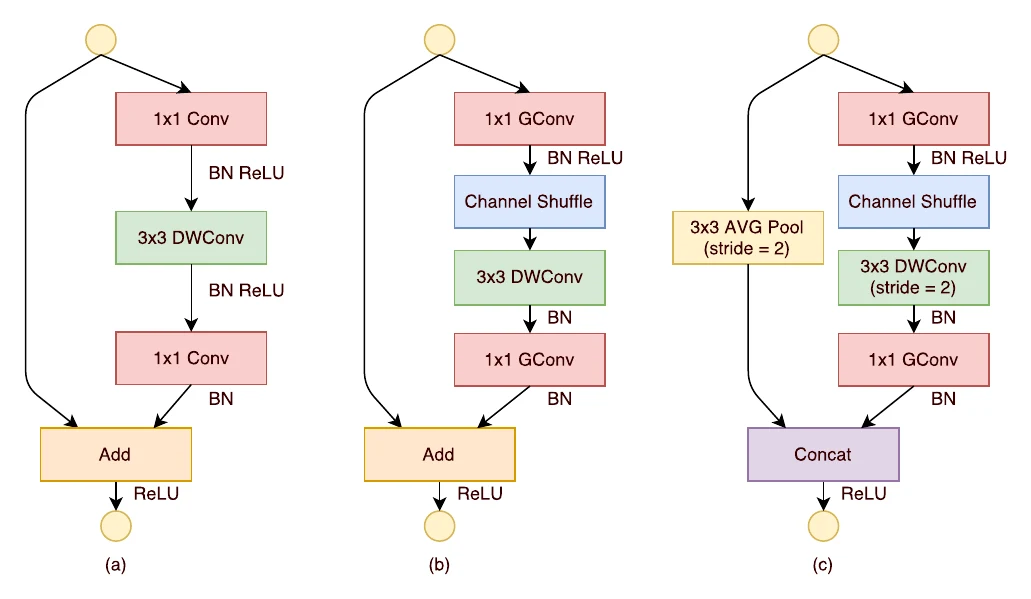
整个 ShuffleNet 由多个 block 堆叠而成:
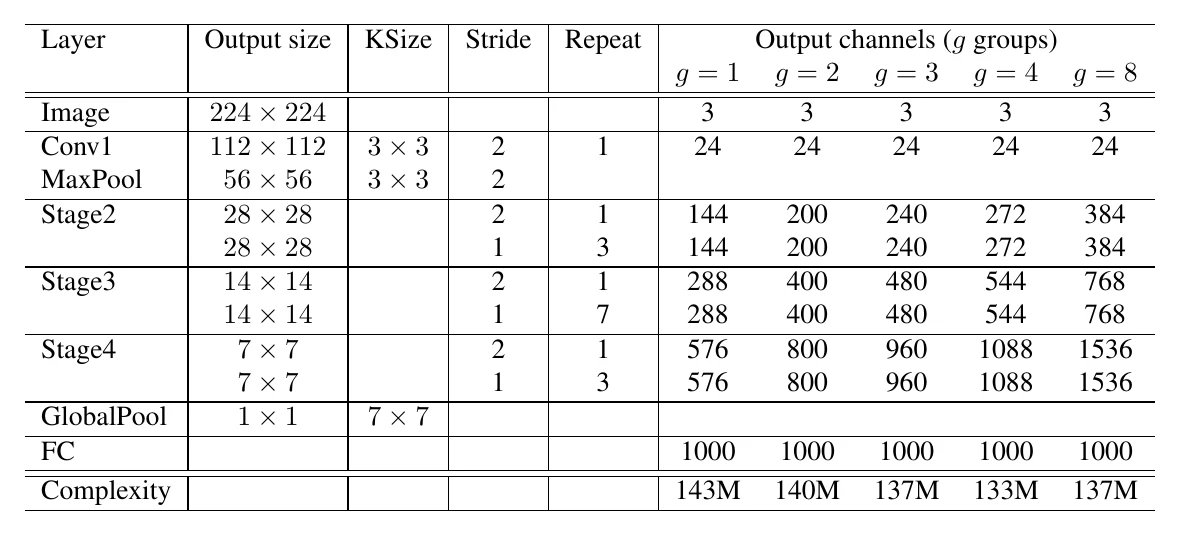
定量看:channel shuffle 本身不增减 FLOPs/参数量,但会改变特征图在内存中的布局,给下一层带来带 stride 的访存开销。而分组数为 的 卷积,其 FLOPs 为 ——相比标准 卷积,FLOPs 和参数量都降为 。固定网络总 FLOPs 时,分组越多就能用更多滤波器,要取得最高精度需要在二者间仔细权衡。
MobileNetV2:Inverted Residual
MobileNetV2 把 ResNet 的残差连接和 bottleneck 融进了 MobileNet,但用的是相反的 inverted bottleneck:先用 卷积把通道数升上去,再做深度可分离卷积,最后用第二个 卷积把通道降回输入的大小。
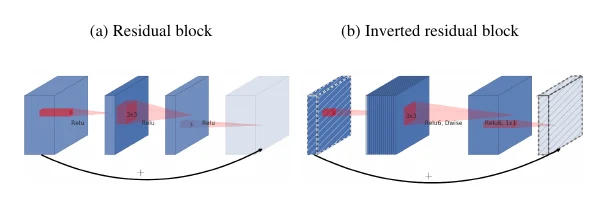
它没有再发明新的紧凑操作,而是把残差连接、bottleneck 这些提升拟合能力的手段融进紧凑网络,进一步提了精度。值得一提的是,MobileNetV2 后来成了很多结构搜索方法的 backbone(下面的 MobileNetV3、EfficientNet 都基于它)。
ShuffleNetV2:从访存开销出发的四条准则
ShuffleNetV2 在论文里重点讨论了一个常被忽略的指标——访存开销(MAC, Memory Access Cost),并据此提出四条紧凑网络设计准则。
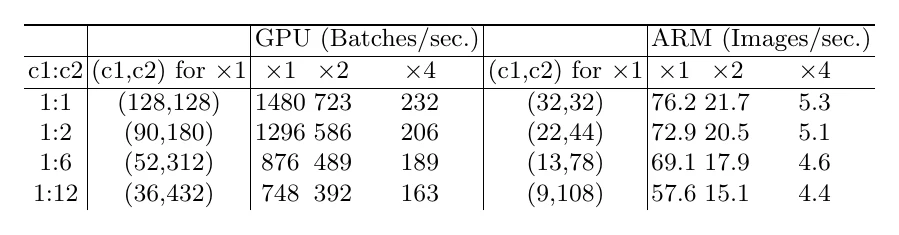
准则一:尽量让卷积的输入输出通道数相同。 以 卷积为例,输入输出通道 、特征图 ,则 。固定 FLOPs 时,访存开销
由均值不等式,MAC 有下限,且在 时取到。实验也证实:同样 FLOPs 下,输入/输出通道比为 时实测最快(GPU 和 ARM 上结论一致)。
准则二:分组数过多会增大 MAC。 分组数为 的 卷积:
固定 FLOPs 时,MAC 随 增大而增大。
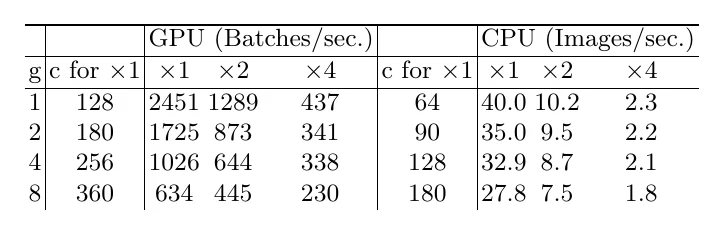
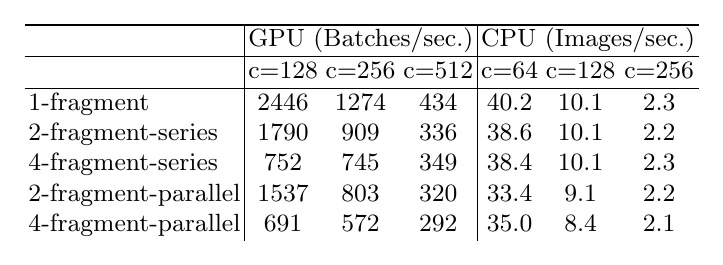
准则三:碎片(fragment)过多会降低并行度。 网络里串行/并行的小分支太多,会削弱并行计算的程度。但深层结构往往精度更高,所以要在精度和并行提速之间权衡。
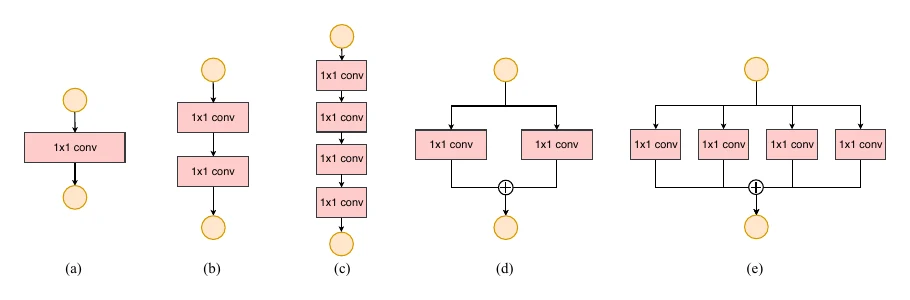
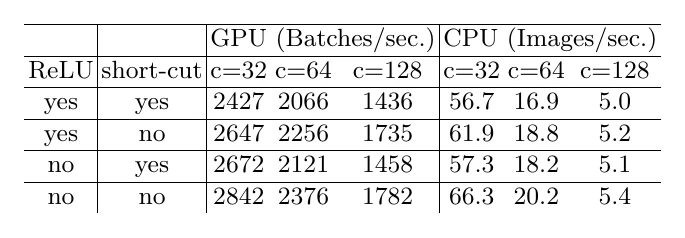
准则四:别忽略 element-wise 操作的开销。 一个操作的时间由 MAC 和 FLOPs 两部分组成。卷积的 FLOPs 远大于 MAC,但点加(element-wise add)、ReLU 这类 FLOPs 很小的操作里,MAC 才是主要开销,不能忽略。
据此,ShuffleNetV2 的 block 与 V1 几乎完全不同:不再用分组 卷积,改用 channel split(既保残差连接,又不因分组卷积增 MAC,准则二);block 里的 Channel Split、Concat、Channel Shuffle 还能融合成一个操作以减小 MAC(准则四)。
MobileNetV3:h-swish
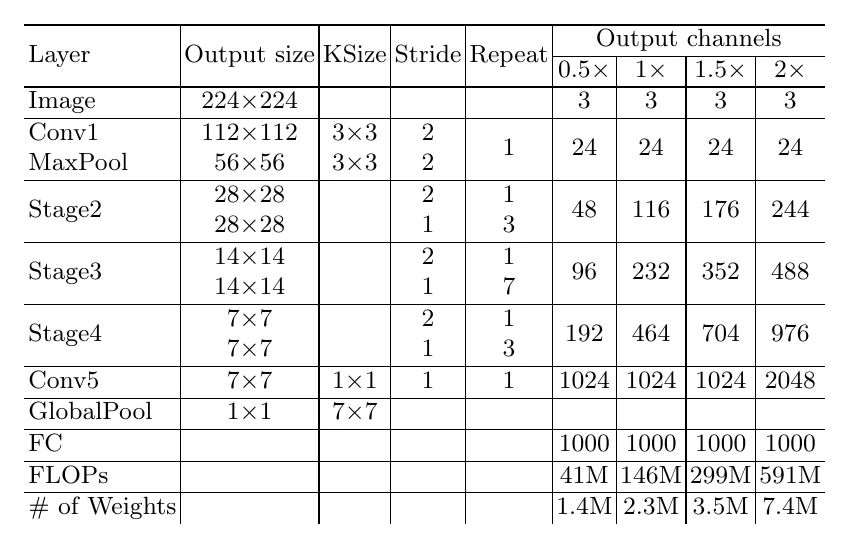
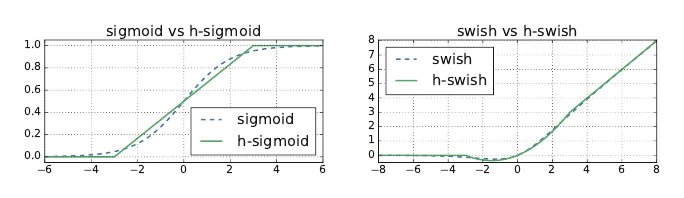
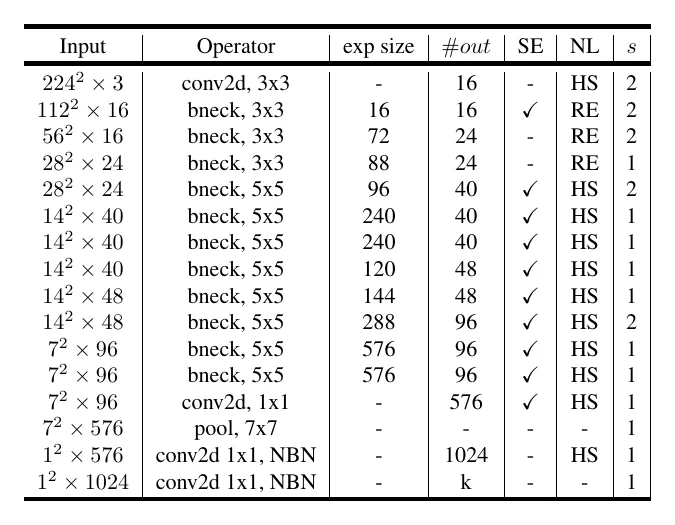
MobileNetV3 是在 MobileNetV2 基础上用自动化搜索(MnasNet + NetAdapt 压缩)得到的,主要改了卷积层数、卷积核大小、通道数,并在部分层用了 SE 模块。此外它把深层的激活函数从 ReLU 换成 hard-swish:
原始的 swish 是 ,但 sigmoid 计算量大;hard-swish 用近似换来了几乎一样的效果、却便宜得多。
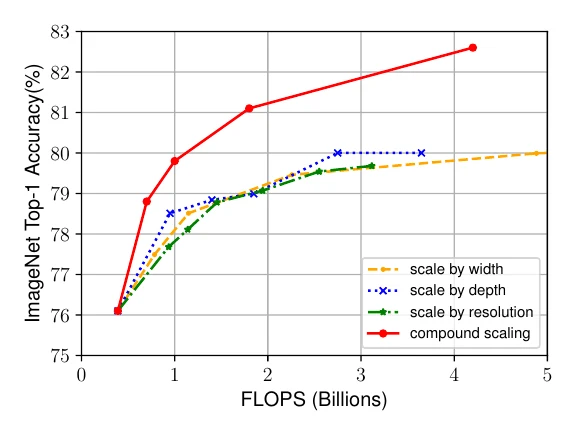
EfficientNet:复合缩放
EfficientNet 与 MobileNetV3 几乎同时诞生,也基于 MnasNet 搜索而来,但搜索只用了简单的网格搜索。它的核心是一套网络缩放方法:既然一个紧凑网络能在很小的 FLOPs 下达到不错精度,那要更高精度,直接把它放大就好。缩放分三个维度:宽度、深度、输入分辨率。
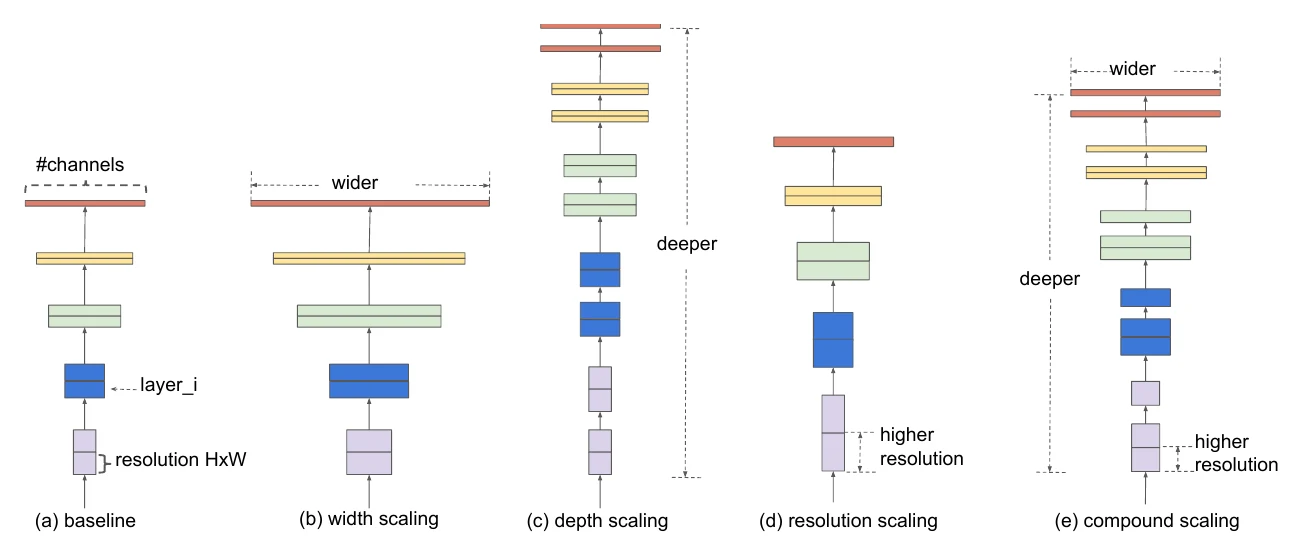
每个维度的缩放倍数解耦成一个相对因子和一个整体因子 :
约束 的原因:FLOPs 随宽度、分辨率以平方增长,随深度线性增长,把 约束成常数,就能让任意缩放都把 FLOPs 维持在可控水平。搜索时固定 、用网格搜索找最佳 ,之后调 就能把网络缩放到任意 FLOPs。
GhostNet:用廉价操作生成”幽灵”特征
GhostNet 同样走分解路线,但出发点很独特:可视化特征图会发现,很多通道的特征图彼此非常相似——那就没必要都用昂贵的标准卷积去算。

于是 GhostNet 把标准卷积分两步:先用更少滤波器的标准卷积算出一部分输出,再用廉价操作(如线性变换/深度可分离卷积)在其基础上”生成”另一部分输出,最后 concat 到一起。
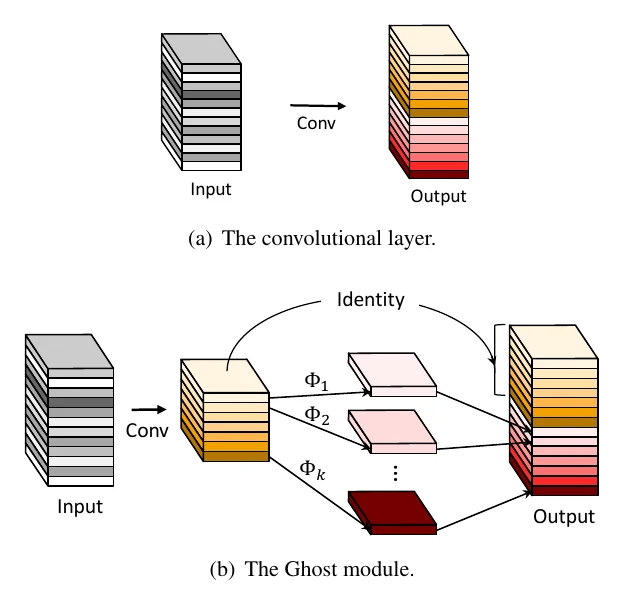
定量分析:卷积核 、输入通道 、输出 ,标准卷积 FLOPs 为 。Ghost 模块若第一步算 个通道、廉价操作用大小为 的深度可分离卷积、令 ,则加速比
(近似用到了 和 。)参数量的压缩比同样约为 。
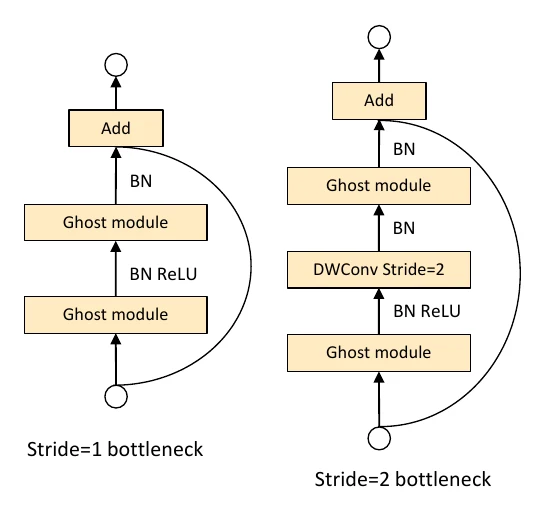
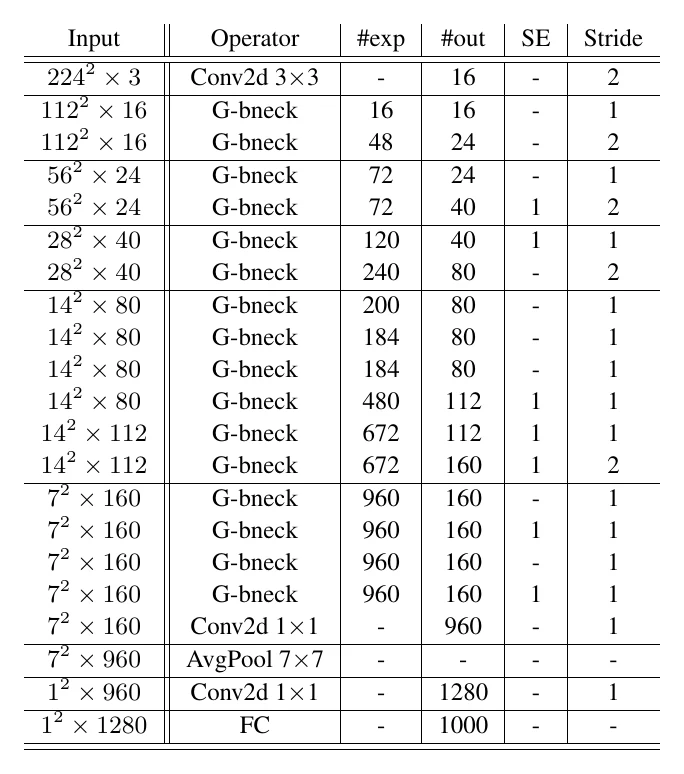
从 MobileNet 把卷积拆开,到 ShuffleNetV2 盯住访存、再到 GhostNet 复用相似特征——紧凑网络设计的主线,始终是在 FLOPs、访存与精度之间反复权衡。而 MobileNetV3、EfficientNet 已经把”人来设计”换成了”自动搜索”,这正是神经网络结构搜索(NAS)的方向。
参考资料
- Howard, Andrew G., et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv:1704.04861, 2017.
- Zhang, Xiangyu, et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. CVPR, 2018.
- Ma, Ningning, et al. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. ECCV, 2018.
- Sandler, Mark, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks. CVPR, 2018.
- Howard, Andrew, et al. Searching for MobileNetV3. arXiv:1905.02244, 2019.
- Tan, Mingxing, Le, Quoc V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv:1905.11946, 2019.
- Han, Kai, et al. GhostNet: More Features from Cheap Operations. CVPR, 2020.
- Tan, Mingxing, et al. MnasNet: Platform-Aware Neural Architecture Search for Mobile. CVPR, 2019.
- Jia, Yangqing, et al. Caffe: Convolutional Architecture for Fast Feature Embedding. ACM MM, 2014.
- Lavin, Andrew, Gray, Scott. Fast Algorithms for Convolutional Neural Networks (Winograd). CVPR, 2016.