Pruning Convolutional Networks: Plan, Cut, Fine-tune
Pruning is a common way to accelerate and compress neural networks, going all the way back to LeCun’s Optimal Brain Damage in 1989. The idea is to remove the “unimportant” parts of a network, and the process usually breaks into three steps:
- Based on an overall target, decide the pruning scheme — the pruning rate for each layer (sometimes called compression rate or sparsity).
- Cut the corresponding layers at the given rates.
- Fine-tune the network to win back the accuracy that pruning cost.
Steps 2 and 3 are often iterated many times, cutting a little at a time and approaching the target gradually. That’s the flow with a pretrained model; without one, you can prune while training. Let’s take them in order.
Deciding the pruning scheme
Before pruning there’s usually an overall target (parameters, peak memory, FLOPs, latency). The point of the scheme is to allocate per-layer pruning rates sensibly so that, while meeting the target, accuracy drops as little as possible. Two approaches: hand-designed and automatic.
Hand-designed
The crudest is experience. Early conv layers in a CNN extract the most primitive image features and everything deeper depends on them, so shallow layers shouldn’t be cut too hard; a downsampling conv layer (e.g. ) has a smaller output map, so it needs more filters retained to keep enough channels and avoid losing feature information.
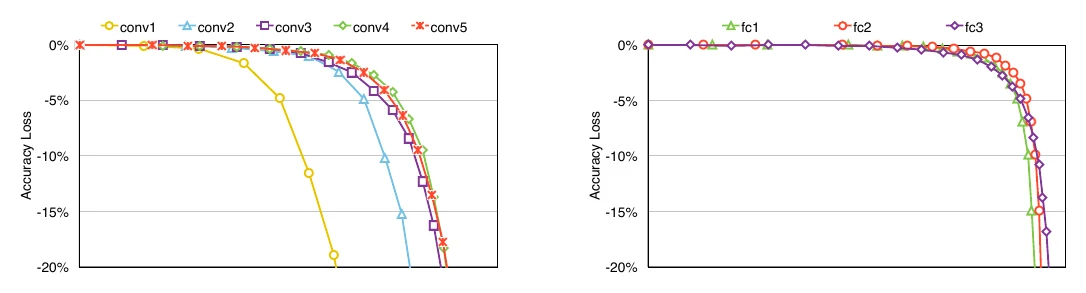
A more principled option is pruning sensitivity analysis: for each layer, prune away different fractions of its parameters and record how much accuracy drops. If a layer loses a lot of accuracy from a small cut, it’s “sensitive” and should keep more parameters when the whole network is pruned. Below is a sensitivity analysis of AlexNet’s layers, and it matches intuition: the early conv layer with only 3 input channels is the most sensitive to pruning; conv layers have fewer parameters than FC layers and do the heavy lifting on feature extraction, so they’re more sensitive too.
Automatic
One automatic approach sets a single global importance threshold and cuts every weight (unstructured) or filter (structured) below it — a layer with more low-importance parts gets pruned harder, with no need to hand-specify per-layer rates.
The other is search. It closely resembles neural architecture search (NAS): both look for the most accurate structure under a resource budget, except automatic pruning usually cares about just one dimension — filter counts — so the search space is smaller, it can start from a pretrained model, and it’s far simpler than NAS.
AMC uses DDPG (a reinforcement-learning method) to search per-layer compression rates. In RL terms: the environment is model pruning, the state is the current pruning progress, the action is this layer’s pruning rate, the reward is the optimization target.
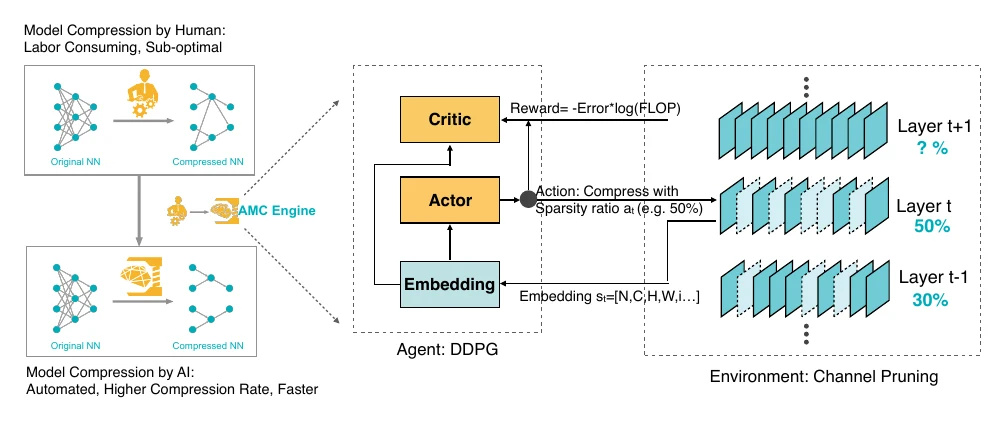
The state and reward are the interesting parts. The state includes the pruned layer’s index, its conv-weight dimensions, its FLOPs, the FLOPs already removed, the FLOPs still to remove, and the previous layer’s pruning rate — because pruning proceeds layer by layer, the “FLOPs still to remove” term is needed to bound this layer’s minimum compression so the final network doesn’t fall short of the target. The reward carries not just error rate but a FLOPs penalty. As with NAS, the most time-consuming part is model validation (from action to reward); AMC sidesteps the costly fine-tune by recalibrating pruned weights with least squares on a small calibration set — at the cost of limited accuracy gains.
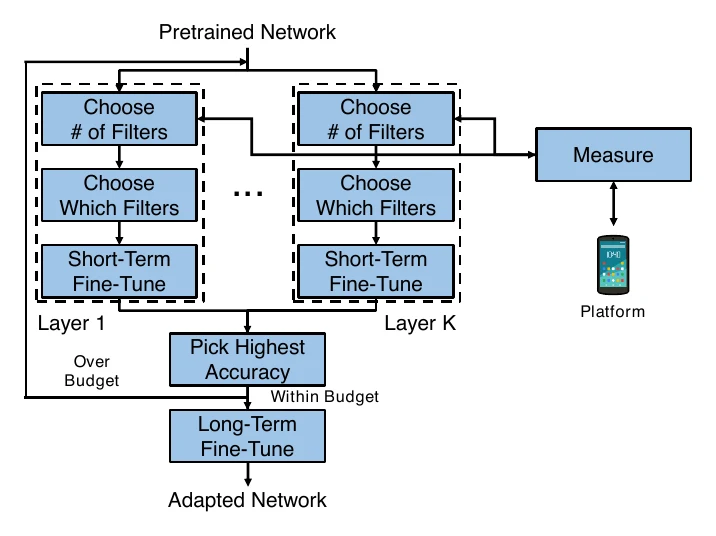
NetAdapt is iterative: each round prunes different layers to generate several candidate proposals, briefly fine-tunes, and picks the most accurate one to advance, until latency meets a specific hardware’s requirement.
MetaPruning and EagleEye both speed up candidate validation: MetaPruning uses a PruningNet to generate the pruned weights directly, skipping most fine-tuning; EagleEye, like SPOS in NAS, only runs calibration data forward once after pruning to recompute BN’s mean and variance, again avoiding the fine-tune cost.
Doing the pruning
Once per-layer rates are set, you cut. Two routes: unstructured pruning that sparsifies weights, and structured pruning that removes whole filters/blocks.
Unstructured pruning
Unstructured pruning sparsifies the weights: it zeroes out the unimportant ones (equivalent to removing connections between neurons). This saves space when storing the network, but to actually accelerate at runtime it needs special software (high-performance sparse matrix multiply) or hardware support (e.g. the NVIDIA A100 Tensor Core GPU).
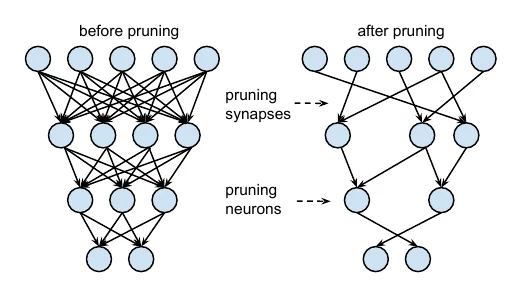
The classic method is Learning both Weights and Connections: during training it trains not only the weights but also the connections, pruning through learning, in three steps —
- Train the network normally (usually with an L1 or L2 penalty on the weights);
- Remove (zero out) weights below a threshold to get sparse weights;
- Re-train to adjust the remaining weights (i.e. fine-tune).
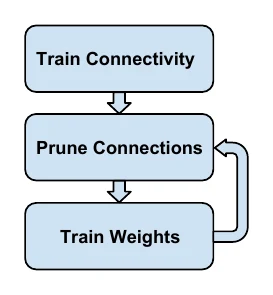
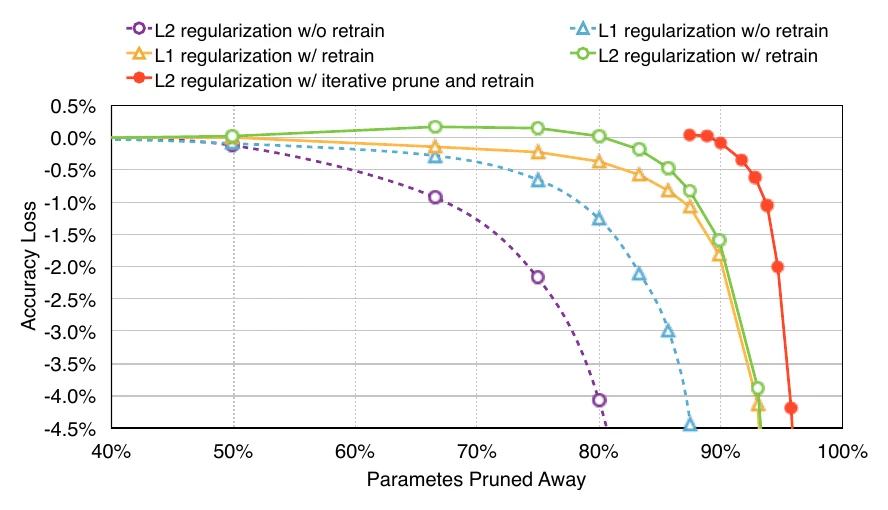
These three steps are usually iterated many times, cutting some connections each round and gradually sparsifying the network. Experiments show that re-training (fine-tuning) after cutting, and iterative rather than one-shot pruning, are both crucial to limiting accuracy loss.
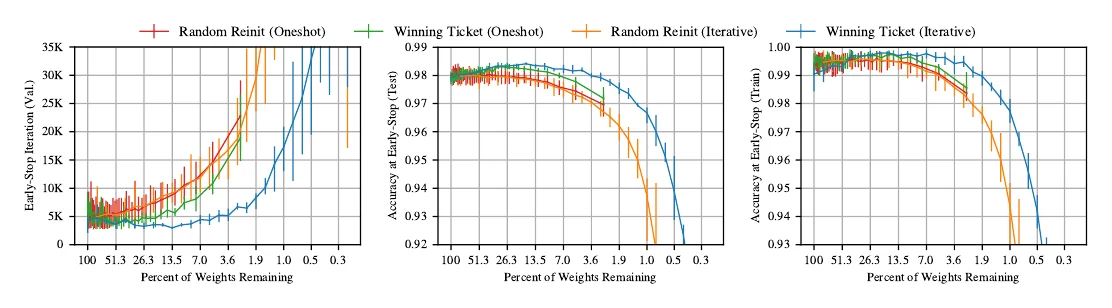
A fascinating line of work is the Lottery Ticket Hypothesis: inside a randomly initialized, unpruned dense network there exists a sub-network that — keeping the same initial parameters — can match the original’s accuracy in the same or fewer training iterations. That sub-network is the winning ticket, found like so:
- Randomly initialize a network ;
- Train it times to get parameters ;
- Prune the smallest of to get a mask ;
- Reset the remaining parameters back to , giving the winning ticket .
As before, iterating is better: to reach a pruning rate, do rounds cutting each. Experiments show iterative beats one-shot, and keeping the initial parameters () beats re-initializing randomly.
Structured pruning
Structured pruning achieves real compression and speedup without special hardware or software, so it’s more common. It usually removes whole filters from a conv layer, which splits in two: how many filters to cut from a given layer, and by what criterion to choose which ones. The “how many” part was covered above (sensitivity analysis, global importance ranking, automatic methods); the focus here is the criterion — the filter importance criteria. They fall into two classes by whether they need data.
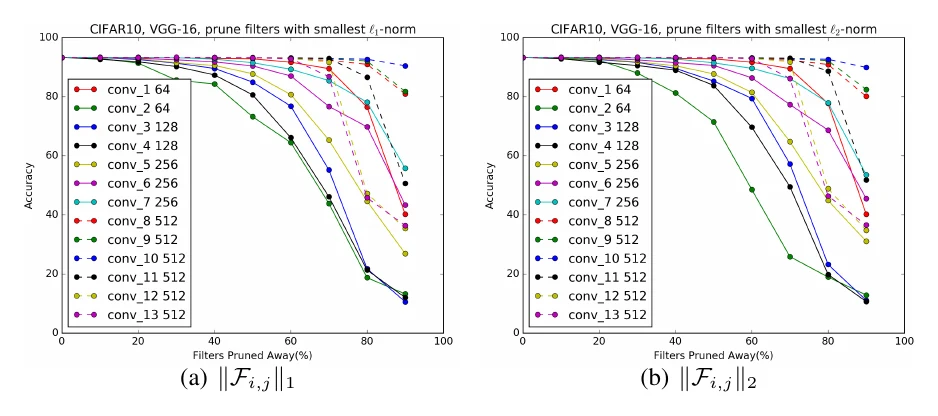
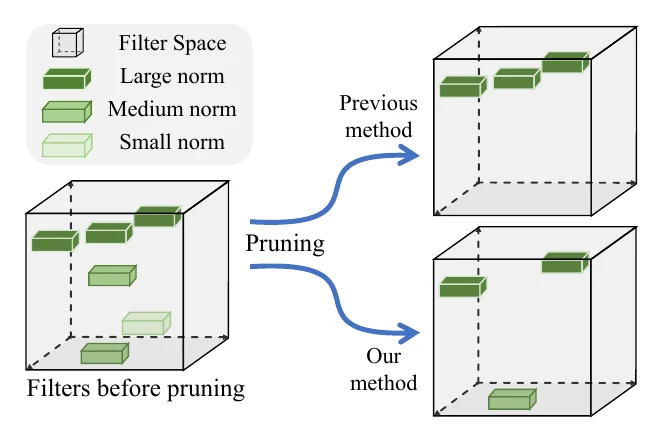
Data-independent methods need only the pretrained weights, ranking by the conv weights themselves. L1 pruning is simplest: take the L1 norm of a filter’s weights as its importance — filter with weights has importance , and small norms are deemed unimportant; L2 pruning is the same with . The two barely differ in effect.
FPGM instead uses the geometric median of the filter weights: for a layer with filters, filter ‘s importance is . Unlike L1/L2, FPGM keeps both large-norm and small-norm filters — what it cuts is the redundant ones, those too similar to the others.
Network Slimming judges by the BN layer. A conv layer is usually followed by BN for normalization and an affine transform; if a filter’s output ends up multiplied by a (the channel scaling factor) near 0, its contribution to later layers is also near 0 and it can be considered unimportant. To make sufficiently sparse, an L1 penalty is added to during training.
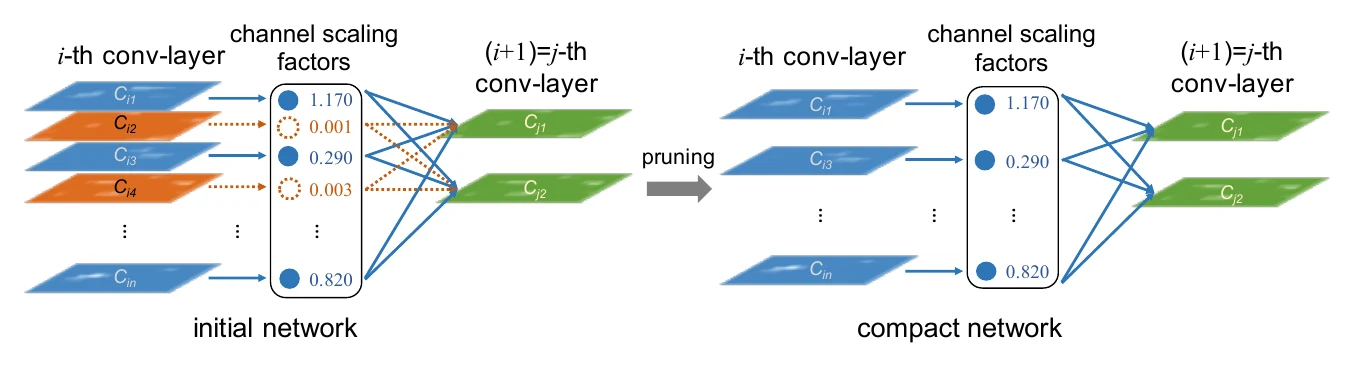
L1/L2, FPGM, and Network Slimming all rely only on pretrained weights. Data-dependent methods instead use calibration data, ranking by the conv outputs on that data; because the criterion is tightly coupled to the target data, they often lose less accuracy at the same compression. Network Trimming proposes APoZ (Average Percentage of Zeros) — after BN and ReLU, a filter whose activations contain many zeros contributes little and can be safely cut; Molchanov et al. also propose using the mean or standard deviation of activations. HRank notes that each filter produces one output feature map (a matrix) and uses that matrix’s rank as importance: higher rank means more information, so it’s worth keeping.
A caveat: the calibration data for data-dependent methods should be randomly sampled from the training set to share its distribution; otherwise the accuracy loss can be worse than a data-independent method’s.
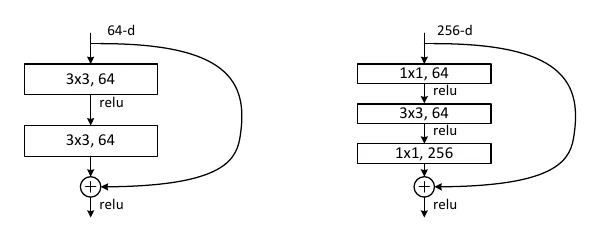
One more thing: structured pruning changes the network’s structure, so you must keep each layer’s input/output dimensions matched after cutting — especially for residual connections. In a ResNet residual block, the main path and the shortcut can’t be added if their dimensions disagree. A common trick: make the last conv layer of a block have as many filters as the input feature map’s channels, so the two sides match when added.
Pruning while training
Everything above prunes a trained model. Without a pretrained model — besides “train first, then prune” or “just use NAS to search a more compact structure” — you can also prune while training.
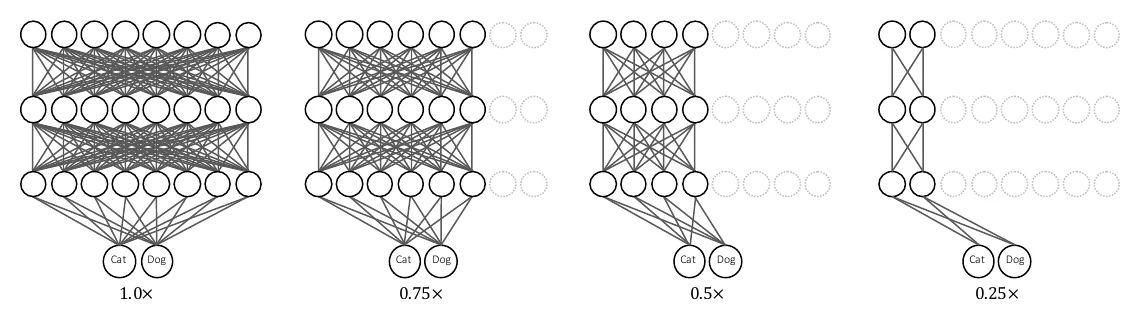
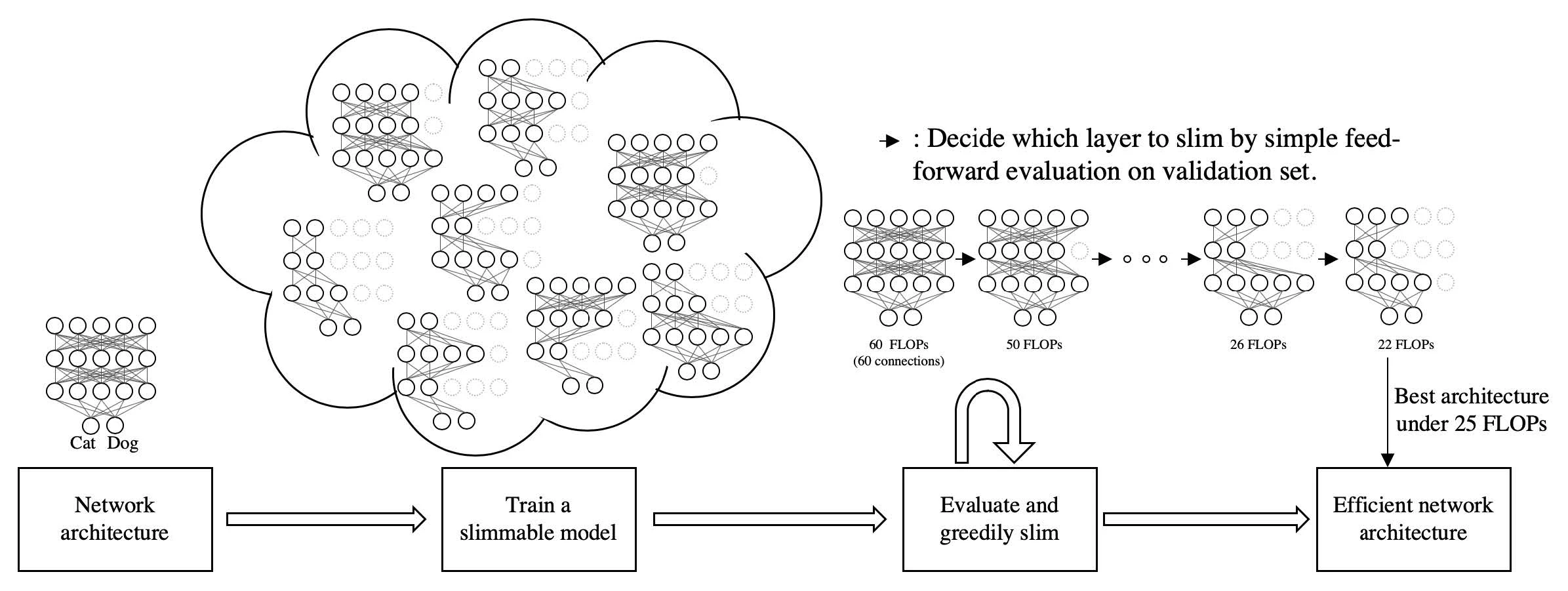
Slimmable Networks use a special training scheme that lets a single network run at different widths. Each batch is forwarded through sub-networks of several widths, each computing a loss and backpropagating gradients, which are then accumulated before updating parameters. Two keys: Switchable BN — each width gets its own independent BN parameters () — and accumulating gradients across widths before the update.

Universally Slimmable Networks builds on this with the sandwich rule and inplace distillation to improve performance further.

AutoSlim’s automatic pruning is nearly identical to NetAdapt — greedy, iterative pruning until FLOPs/latency hit the target — the main difference being that AutoSlim starts from a trained slimmable network while NetAdapt starts from an ordinary pretrained model.
References
- LeCun, Yann, et al. Optimal Brain Damage. NeurIPS, 1989.
- Han, Song, et al. Learning both Weights and Connections for Efficient Neural Networks. NeurIPS, 2015.
- Frankle, Jonathan, Carbin, Michael. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. arXiv:1803.03635, 2018.
- Li, Hao, et al. Pruning Filters for Efficient ConvNets. arXiv:1608.08710, 2016.
- Liu, Zhuang, et al. Learning Efficient Convolutional Networks through Network Slimming. ICCV, 2017.
- He, Yang, et al. Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration (FPGM). CVPR, 2019.
- Hu, Hengyuan, et al. Network Trimming: A Data-Driven Neuron Pruning Approach. arXiv:1607.03250, 2016.
- Molchanov, Pavlo, et al. Pruning Convolutional Neural Networks for Resource Efficient Inference. arXiv:1611.06440, 2016.
- Lin, Mingbao, et al. HRank: Filter Pruning using High-Rank Feature Map. CVPR, 2020.
- He, Yihui, et al. AMC: AutoML for Model Compression and Acceleration on Mobile Devices. ECCV, 2018.
- Yang, Tien-Ju, et al. NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications. ECCV, 2018.
- Liu, Zechun, et al. MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning. ICCV, 2019.
- Li, Bailin, et al. EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning. arXiv:2007.02491, 2020.
- Guo, Zichao, et al. Single Path One-Shot Neural Architecture Search with Uniform Sampling (SPOS). ECCV, 2020.
- Yu, Jiahui, et al. Slimmable Neural Networks. arXiv:1812.08928, 2018.
- Yu, Jiahui, Huang, Thomas S. Universally Slimmable Networks and Improved Training Techniques. ICCV, 2019.
- Yu, Jiahui, Huang, Thomas. AutoSlim: Towards One-Shot Architecture Search for Channel Numbers. arXiv:1903.11728, 2019.
- Ioffe, Sergey, Szegedy, Christian. Batch Normalization. arXiv:1502.03167, 2015.
- He, Kaiming, et al. Deep Residual Learning for Image Recognition. CVPR, 2016.