卷积神经网络剪枝:确定方案、动手剪、再微调
模型剪枝(pruning)是神经网络加速与压缩的常见手段,最早可以追溯到 1989 年 LeCun 的 Optimal Brain Damage。它的思路是把网络里”不重要”的部分去掉,整个过程通常分三步:
- 先根据总体目标,确定模型的剪枝方案——也就是每一层的剪枝率(有时也叫压缩率、稀疏率)。
- 再把对应的层按给定的剪枝率剪掉。
- 最后对网络做微调(finetune),把剪枝带来的精度损失补回来。
第 2、3 步往往会迭代多次,每次只剪一部分,用渐进的方式逼近总体目标。上面是带预训练模型的剪枝流程;没有预训练模型时,也可以一边训练一边剪。下面依次来看。
确定剪枝方案
剪枝之前通常有一个整体目标(参数量、峰值内存、FLOPs、时延等),确定方案的目的,是在满足目标的前提下合理分配每层剪枝率,让精度损失最小。有两类做法:手工设计和自动设计。
手工设计
最朴素的是凭经验。比如 CNN 里靠前的卷积层负责提取最原始的图像特征,深层都依赖浅层的输出,所以浅层不宜剪得太狠;再比如做了下采样的卷积层(如 ),输出特征图变小了,需要保留更多滤波器来维持足够的通道数,以免丢掉太多特征信息。
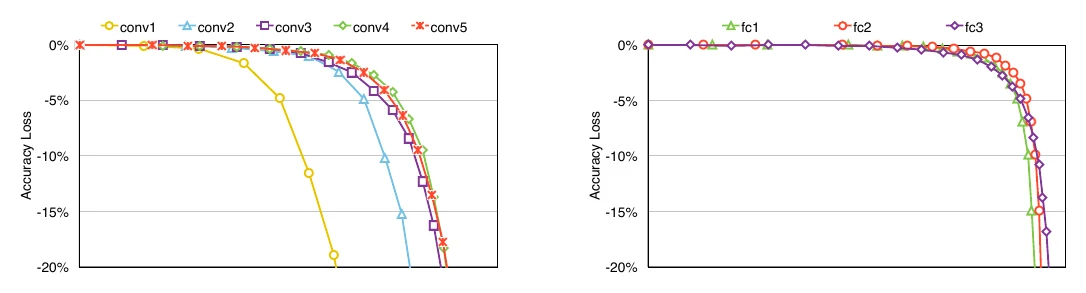
更科学一点的是剪枝敏感度分析。对每一层分别剪掉不同比例的参数,统计精度下降的程度:如果某层只剪掉很少参数就掉点很厉害,说明它很”敏感”,剪整个网络时就该在这层多留些参数。下图是对 AlexNet 各层做的敏感度分析,结果和直觉一致:靠前、只有 3 个输入通道的卷积层对剪枝最敏感;卷积层比全连接层参数更少、又承担主要的特征提取,因此也更敏感。
自动设计
一种自动方式是设一个全局的重要性阈值,把所有低于阈值的权重(非结构化)或滤波器(结构化)剪掉——某层里低重要性的越多,它自然就被剪得越狠,不必再手工指定每层比例。
另一种是搜索。它和神经网络结构搜索(NAS)很像,目标都是在资源约束下搜出精度最高的结构,只是自动剪枝通常只关注滤波器数量这一个维度,搜索空间更小、可以直接从预训练模型出发,因此比 NAS 简单不少。
AMC 用强化学习里的 DDPG 来逐层搜索压缩率。以强化学习的视角看:环境是模型剪枝,状态是当前剪枝进度,动作是这一层的剪枝率,奖励是优化目标。
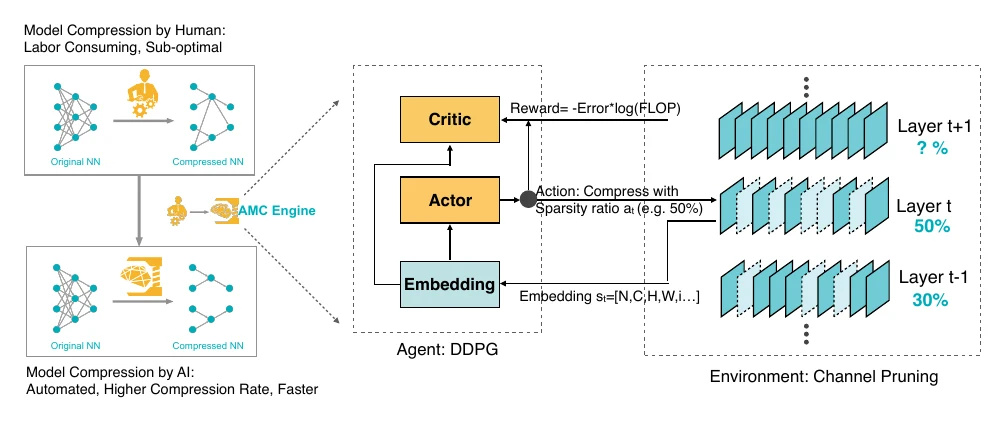
这里值得关注的是状态和奖励。状态包含剪枝层的索引、卷积权重维度、该层 FLOPs、已剪掉的 FLOPs、剩余待剪的 FLOPs,以及上一层的剪枝率——因为剪枝逐层进行,得在状态里加入”剩余待剪 FLOPs”来约束当前层的压缩下限,免得剪完整体达不到目标。奖励里不只有误差率,还带了 FLOPs 的惩罚项。和 NAS 一样,自动剪枝最耗时的环节是模型验证(从动作到奖励这一段);AMC 借助一小部分标定数据、用最小二乘重新校准剪枝层权重,避开了耗时的 finetune,代价是精度提升有限。
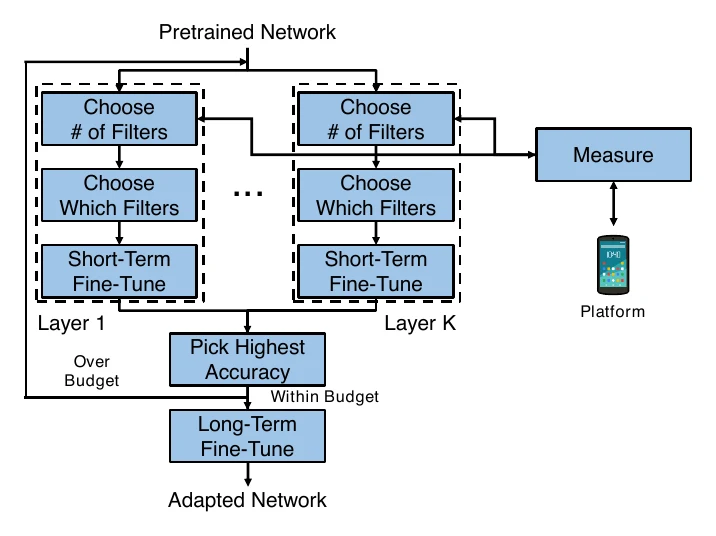
NetAdapt 则是迭代式的:每轮对不同层剪枝生成若干候选方案(proposal),短暂 finetune 后选出精度最高的进入下一轮,直到时延满足特定硬件的要求。
MetaPruning 和 EagleEye 都在”加速候选验证”上想了办法:MetaPruning 用一个 PruningNet 直接生成剪枝后的权重,省去大量 finetune;EagleEye 则和 NAS 里的 SPOS 一样,剪枝后只用标定数据做一次前向、重新校准 BN 的均值与方差,同样绕开了 finetune 的时间开销。
对模型进行剪枝
定好每层剪枝率后,就是动手剪。两条路线:对权重做稀疏的非结构化剪枝,和剪掉整个滤波器/模块的结构化剪枝。
非结构化剪枝
非结构化剪枝是对权重做稀疏:把其中不重要的部分置零(等价于移除神经元之间的连接)。这样存储网络时能省空间,但实际计算时要靠特殊的软件实现(如高性能稀疏矩阵乘)或硬件支持(如 NVIDIA A100 Tensor Core GPU)才能真正加速。
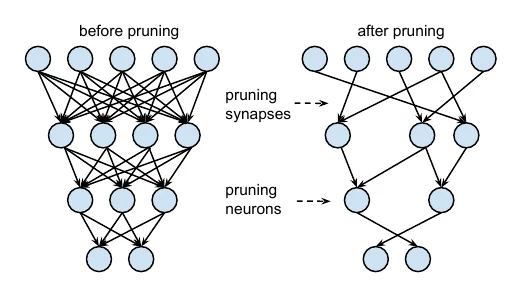
经典方法是 Learning both Weights and Connections:训练时不仅训练权重,也”训练”连接,通过学习来剪枝,分三步——
- 按正常方式训练好网络(过程中通常对权重加 L1 或 L2 惩罚);
- 把权重里低于某个阈值的部分移除(置零,得到稀疏权重);
- 再训练调整剩下的权重(即 finetune)。
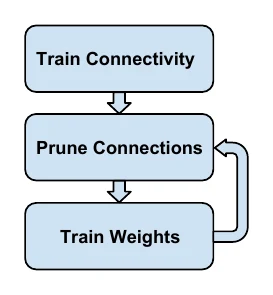
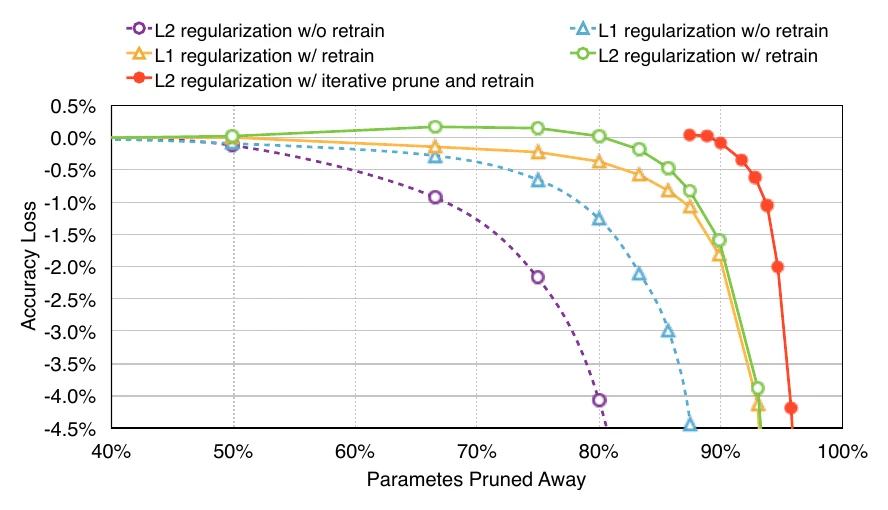
这三步通常迭代多次,每次只剪一部分连接,渐进地把网络压到很稀疏的状态。实验表明:剪完之后 retrain(finetune),以及用迭代式而非一次性的剪枝,对减小精度损失都很关键。
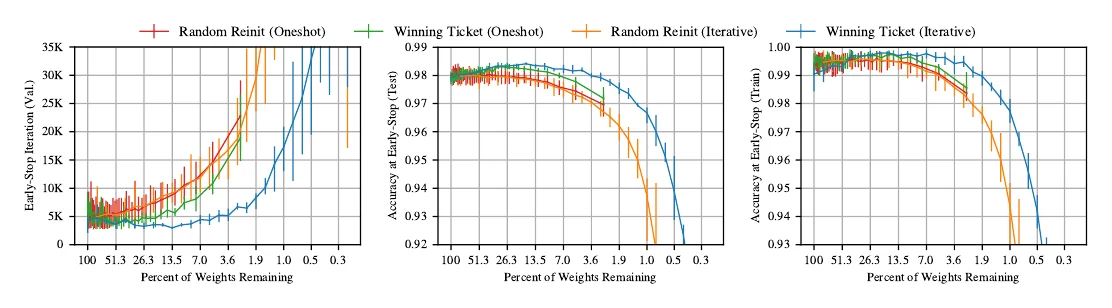
另一项很有意思的工作是彩票假设(Lottery Ticket Hypothesis):一个随机初始化、未剪枝的稠密网络里,一定存在一个子网络——在保持相同初始化参数的前提下,经过相同或更少的训练就能达到与原网络相同的精度。这个子网络叫 winning ticket,找它的方法是:
- 随机初始化网络 ;
- 训练 次,得到参数 ;
- 剪掉 中最小的 参数,得到掩码 ;
- 把剩余参数重置回 ,得到 winning ticket 。
和上面一样,迭代式同样更优:要实现 的剪枝率,可以分 次、每次剪 。实验显示,迭代式优于一次性(oneshot),而保留初始参数()又优于重新随机初始化。
结构化剪枝
结构化剪枝不需要特殊软硬件就能实现真正的压缩与加速,因此更常用。它通常是剪掉卷积层里整个滤波器(filter),问题分两半:某层该剪掉多少个滤波器?以及按什么标准选哪些滤波器剪?前者前面已经讲过(敏感度分析、全局重要性排序、自动化方法),这里重点说后者——滤波器的重要性度量(importance criteria)。按是否依赖数据,分两类。
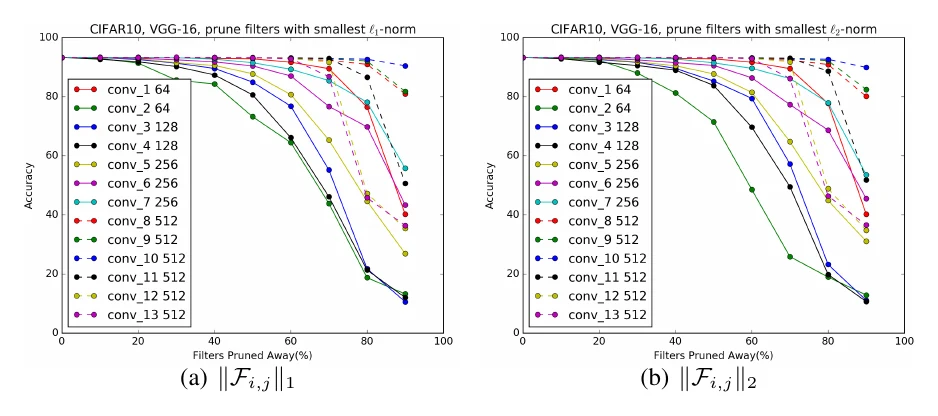
数据无关的方法只需预训练权重,根据卷积权重本身排序。L1 剪枝最简单,直接拿滤波器权重的 L1 范数当重要性:第 个滤波器权重为 ,重要性即 ,范数小的被认为不重要;L2 剪枝同理,改用 。两者差距其实不大。
FPGM 改用滤波器权重的几何中位数(geometric median):若某层有 个滤波器,第 个的重要性为 。和 L1/L2 不同,FPGM 既会保留范数大的滤波器,也会保留范数小的——它剪掉的是”和别人太像、冗余”的那些。
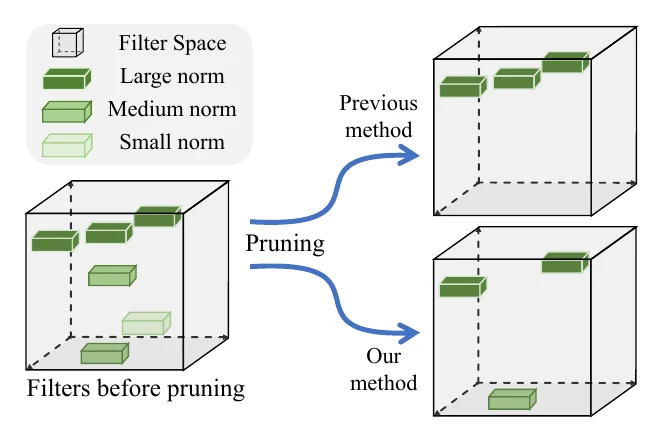
Network Slimming 借 BN 层来判断。卷积后一般接 BN 做归一化与仿射变换,如果某滤波器的输出最终乘上了一个接近 0 的 (channel scaling factor),那它对后面层的贡献也接近 0,可以认为不重要。为了让 足够稀疏,训练时通常对 加 L1 正则。
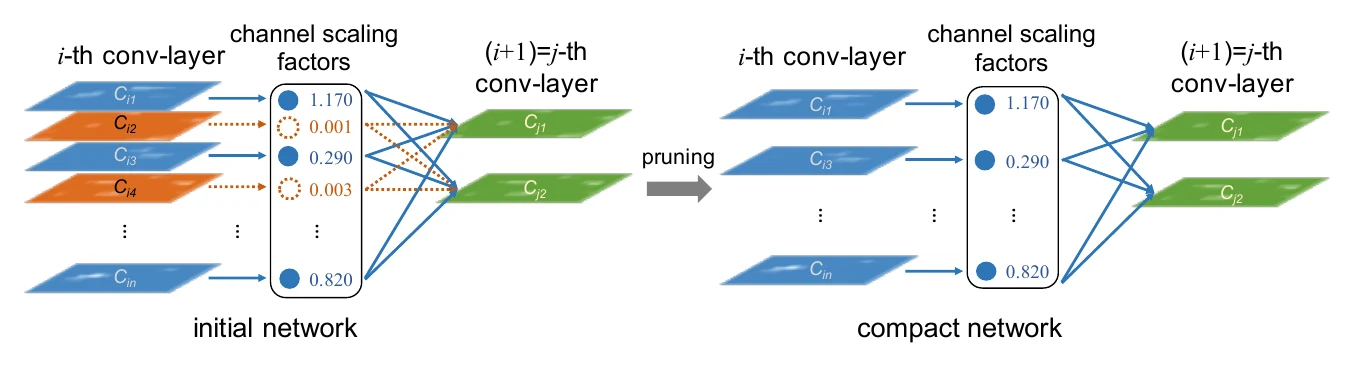
上面 L1/L2、FPGM、Network Slimming 都只看预训练权重。数据依赖的方法则要用标定数据,根据这些数据在卷积层的输出来排序,由于重要性度量和目标数据高度耦合,同样压缩比下往往精度损失更小。Network Trimming 提出用 APoZ(Average Percentage of Zeros)——卷积输出经 BN、ReLU 后,如果某滤波器的激活值里有很多 0,说明它贡献小、可以安全剪掉;Molchanov 等人也提出用激活值的均值或标准差当度量。HRank 则注意到每个滤波器对应输出的一张特征图(一个矩阵),用该矩阵的**秩(rank)**当重要性:秩越高信息量越大,越该保留。
需要提醒:数据依赖的标定数据要从训练集随机采样,保持同分布;否则精度损失可能比数据无关的方法还大。
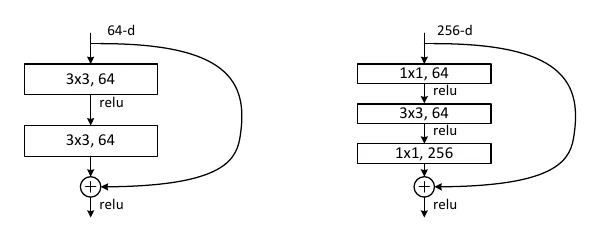
还有一点:结构化剪枝改变了网络原有结构,得保证各层剪完后输入输出维度仍能对上,尤其是带残差连接的结构。以 ResNet 的残差块为例,如果主路与 shortcut 维度不一致就没法相加。常见做法是:让某 block 最后一个卷积层的滤波器数量等于输入特征图的通道数,从而保证相加时通道数一致。
训练过程中剪枝
前面都是对训练好的模型剪枝。如果没有预训练模型,除了”先训练好再剪""直接用 NAS 搜一个更紧凑的结构”,还可以一边训练一边剪。
Slimmable Networks 用一种特殊训练方式,让单个网络能在不同宽度下运行。训练时,每个 batch 在多个宽度的子网络上分别前向、算损失、反向求梯度,最后把这些梯度累加再更新参数。两个关键点:一是用可切换的 BN(Switchable BN)——不同宽度各用一套独立的 BN 参数();二是聚合不同宽度的梯度后再更新。
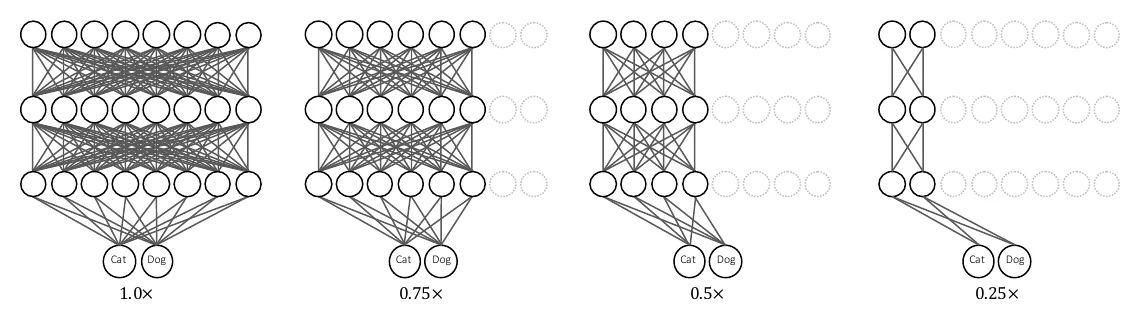

Universally Slimmable Networks 在此基础上提出 sandwich rule 和 inplace distillation,进一步改进了性能。

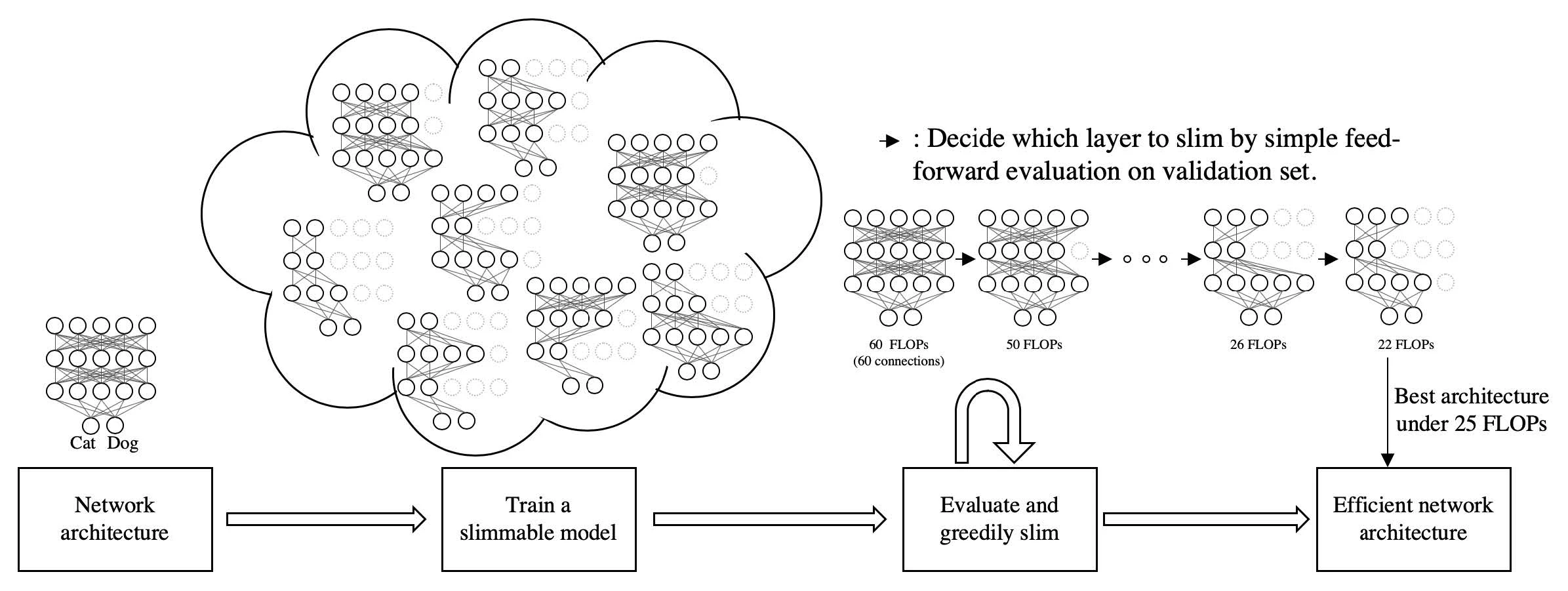
AutoSlim 的自动剪枝思路和 NetAdapt 几乎一样,都是贪心地迭代剪枝,直到 FLOPs/时延达标;最大区别在于 AutoSlim 从一个训练好的 slimmable network 出发,而 NetAdapt 从普通预训练模型出发。
参考资料
- LeCun, Yann, et al. Optimal Brain Damage. NeurIPS, 1989.
- Han, Song, et al. Learning both Weights and Connections for Efficient Neural Networks. NeurIPS, 2015.
- Frankle, Jonathan, Carbin, Michael. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. arXiv:1803.03635, 2018.
- Li, Hao, et al. Pruning Filters for Efficient ConvNets. arXiv:1608.08710, 2016.
- Liu, Zhuang, et al. Learning Efficient Convolutional Networks through Network Slimming. ICCV, 2017.
- He, Yang, et al. Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration (FPGM). CVPR, 2019.
- Hu, Hengyuan, et al. Network Trimming: A Data-Driven Neuron Pruning Approach. arXiv:1607.03250, 2016.
- Molchanov, Pavlo, et al. Pruning Convolutional Neural Networks for Resource Efficient Inference. arXiv:1611.06440, 2016.
- Lin, Mingbao, et al. HRank: Filter Pruning using High-Rank Feature Map. CVPR, 2020.
- He, Yihui, et al. AMC: AutoML for Model Compression and Acceleration on Mobile Devices. ECCV, 2018.
- Yang, Tien-Ju, et al. NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications. ECCV, 2018.
- Liu, Zechun, et al. MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning. ICCV, 2019.
- Li, Bailin, et al. EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning. arXiv:2007.02491, 2020.
- Guo, Zichao, et al. Single Path One-Shot Neural Architecture Search with Uniform Sampling (SPOS). ECCV, 2020.
- Yu, Jiahui, et al. Slimmable Neural Networks. arXiv:1812.08928, 2018.
- Yu, Jiahui, Huang, Thomas S. Universally Slimmable Networks and Improved Training Techniques. ICCV, 2019.
- Yu, Jiahui, Huang, Thomas. AutoSlim: Towards One-Shot Architecture Search for Channel Numbers. arXiv:1903.11728, 2019.
- Ioffe, Sergey, Szegedy, Christian. Batch Normalization. arXiv:1502.03167, 2015.
- He, Kaiming, et al. Deep Residual Learning for Image Recognition. CVPR, 2016.